流水并行
作者: Guangyang Lu, Hongxin Liu, Yongbin Li, Mingyan Jiang
前置教程
示例代码
相关论文
- Colossal-AI: A Unified Deep Learning System For Large-Scale Parallel Training
- Efficient Large-Scale Language Model Training on GPU Clusters Using Megatron-LM
- GPipe: Efficient Training of Giant Neural Networks using Pipeline Parallelism
快速预览
在本教程中,你将学习如何使用流水并行。在 Colossal-AI 中, 我们使用 NVIDIA 推出的 1F1B 流水线。由于在本例中, 使用 ViT 和 ImageNet 太过庞大,因此我们使用 Bert 和 Glue数据集 为例.
目录
在本教程中,我们将介绍:
- 介绍 1F1B 流水线;
- 使用非交错和交错 schedule;
- 使用流水线微调 Bert
认识 1F1B 流水线
首先,我们将向您介绍 GPipe,以便您更好地了解。
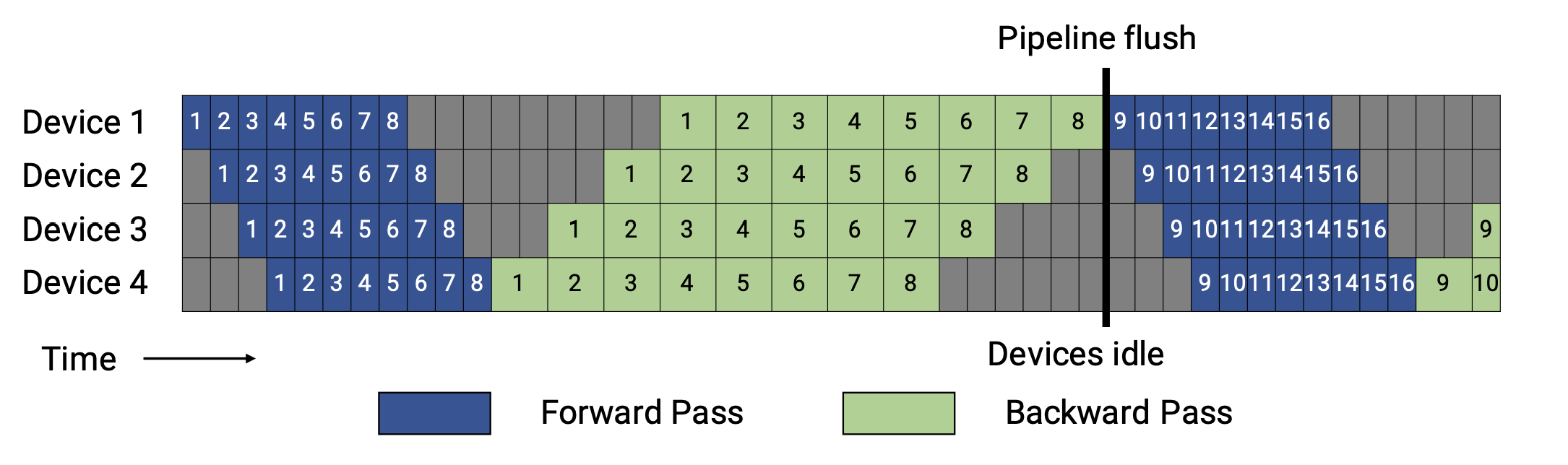
正如你所看到的,对于 GPipe,只有当一个批次中所有 microbatches 的前向计算完成后,才会执行后向计算。
一般来说,1F1B(一个前向通道和一个后向通道)比 GPipe (在内存或内存和时间方面)更有效率。1F1B 流水线有两个 schedule ,非交错式和交错式,图示如下。
非交错 Schedule
非交错式 schedule 可分为三个阶段。第一阶段是热身阶段,处理器进行不同数量的前向计算。在接下来的阶段,处理器进行一次前向计算,然后是一次后向计算。处理器将在最后一个阶段完成后向计算。
这种模式比 GPipe 更节省内存。然而,它需要和 GPipe 一样的时间来完成一轮计算。
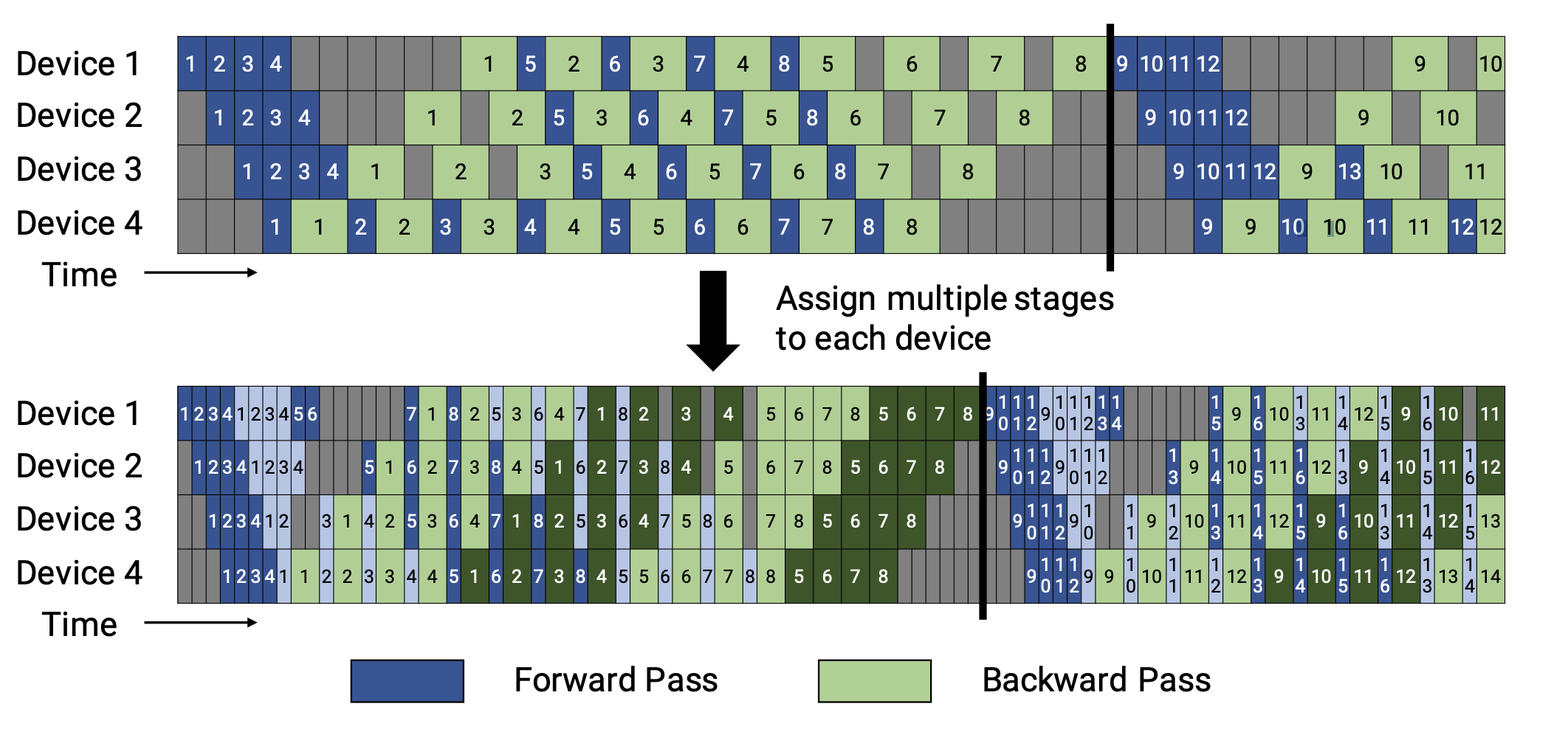
交错 Schedule
这个 schedule 要求microbatches的数量是流水线阶段的整数倍。
在这个 schedule 中,每个设备可以对多个层的子集(称为模型块)进行计算,而不是一个连续层的集合。具体来看,之前设备1拥有层1-4,设备2拥有层5-8,以此类推;但现在设备1有层1,2,9,10,设备2有层3,4,11,12,以此类推。 在该模式下,流水线上的每个设备都被分配到多个流水线阶段,每个流水线阶段的计算量较少。
这种模式既节省内存又节省时间。
Colossal-AI中的实现
在 Colossal-AI 中,流水线并行依赖于 scheduler 和 Shardformer。我们提供了非交错的(OneForwardOneBackwardSchedule)和交错的(InterleavedSchedule)两种调度方式。而 Shardformer 实现了对模型的层分割,并替换了模型的 forward 函数,使其与调度器兼容。
在 Colossal-AI 中,HybridParallelPlugin 封装了流水线执行策略。它管理流水线并行通信组和一个 scheduler。当使用此插件增强模型时,模型的层将通过调用 shardformer.optimize 函数进行分割,然后调用 execute_pipeline 使用 scheduler 来分别执行模型的各个部分。 HybridParallelPlugin暂时只支持OneForwardOneBackwardSchedule, InterleavedSchedule将会在不久后支持。
您可以通过设置 HybridParallelPlugin 的参数来自定义您的并行策略。更多使用细节请参考HybridParallelPlugin的使用文档。
使用流水线微调 Bert模型
首先我们定义好需要的训练组件,包括model, dataloader, optimizer, lr_scheduler, criterion 等:
import argparse
from typing import Callable, List, Union
import torch
import torch.nn as nn
from data import GLUEDataBuilder
from torch.optim import Adam, Optimizer
from torch.optim.lr_scheduler import _LRScheduler as LRScheduler
from torch.utils.data import DataLoader
from tqdm import tqdm
from transformers import (
AlbertForSequenceClassification,
AutoConfig,
BertForSequenceClassification,
get_linear_schedule_with_warmup,
)
import colossalai
from colossalai.booster import Booster
from colossalai.booster.plugin import HybridParallelPlugin
from colossalai.cluster import DistCoordinator
from colossalai.nn.optimizer import HybridAdam
# Define some config
NUM_EPOCHS = 3
BATCH_SIZE = 32
LEARNING_RATE = 2.4e-5
WEIGHT_DECAY = 0.01
WARMUP_FRACTION = 0.1
coordinator = DistCoordinator()
def move_to_cuda(batch):
return {k: v.cuda() for k, v in batch.items()}
# Define 'criterion' function with two inputs, which will be passed to 'execute_pipeline'.
def _criterion(outputs, inputs):
return outputs.loss
# Define optimizer
lr = LEARNING_RATE
no_decay = ["bias", "LayerNorm.weight"]
optimizer_grouped_parameters = [
{
"params": [p for n, p in model.named_parameters() if not any(nd in n for nd in no_decay)],
"weight_decay": WEIGHT_DECAY,
},
{
"params": [p for n, p in model.named_parameters() if any(nd in n for nd in no_decay)],
"weight_decay": 0.0,
},
]
optimizer = HybridAdam(optimizer_grouped_parameters, lr=lr, eps=1e-8)
# Define lr_scheduler
total_steps = len(train_dataloader) * NUM_EPOCHS
num_warmup_steps = int(WARMUP_FRACTION * total_steps)
lr_scheduler = get_linear_schedule_with_warmup(
optimizer,
num_warmup_steps=num_warmup_steps,
num_training_steps=total_steps,
)
# Define Bert model
model = BertForSequenceClassification.from_pretrained("bert-base-uncased", config=cfg).cuda()
# Define a dataloader
data_builder = GLUEDataBuilder(model_name,
plugin,
args.task,
train_batch_size=BATCH_SIZE,
eval_batch_size=BATCH_SIZE)
train_dataloader = data_builder.train_dataloader()
使用HybridParallelPlugin初始化一个booster.
plugin = HybridParallelPlugin(tp_size=1,
pp_size=2,
num_microbatches=None,
microbatch_size=1,
enable_all_optimization=True,
zero_stage=1,
precision='fp16',
initial_scale=1)
booster = Booster(plugin=plugin)
使用booster将优化特性注入到训练组件中。
model, optimizer, _criterion, _, lr_scheduler = booster.boost(model,
optimizer,
criterion=_criterion,
lr_scheduler=lr_scheduler)
最后训练模型
# Define a train function
def train_epoch(epoch: int, model: nn.Module, optimizer: Optimizer, _criterion: Callable, lr_scheduler: LRScheduler,
train_dataloader: DataLoader, booster: Booster, coordinator: DistCoordinator):
is_pp_last_stage = booster.plugin.stage_manager.is_last_stage()
total_step = len(train_dataloader)
model.train()
optimizer.zero_grad()
# convert train_dataloader to a iterator
train_dataloader_iter = iter(train_dataloader)
with tqdm(range(total_step),
desc=f'Epoch [{epoch + 1}/{NUM_EPOCHS}]',
disable=not (is_pp_last_stage)) as pbar:
# Forward pass
for _ in pbar:
outputs = booster.execute_pipeline(train_dataloader_iter,
model,
_criterion,
optimizer,
return_loss=True)
# Backward and optimize
if is_pp_last_stage:
loss = outputs['loss']
pbar.set_postfix({'loss': loss.item()})
optimizer.step()
optimizer.zero_grad()
lr_scheduler.step()
# Train model
for epoch in range(NUM_EPOCHS):
train_epoch(epoch, model, optimizer, _criterion, lr_scheduler, train_dataloader, booster, coordinator)
我们使用 2 个流水段,并且 batch 将被切分为 1 个 micro batches。(这些参数都可根据实际情况设置为合适的值)