Booster 插件
作者: Hongxin Liu, Baizhou Zhang, Pengtai Xu
前置教程:
引言
正如 Booster API 中提到的,我们可以使用 booster 插件来自定义并行训练。在本教程中,我们将介绍如何使用 booster 插件。
我们现在提供以下插件:
- Torch DDP 插件: 它包装了
torch.nn.parallel.DistributedDataParallel并且可用于使用数据并行训练模型。 - Torch FSDP 插件: 它包装了
torch.distributed.fsdp.FullyShardedDataParallel并且可用于使用 Zero-dp 训练模型。 - Low Level Zero 插件: 它包装了
colossalai.zero.low_level.LowLevelZeroOptimizer,可用于使用 Zero-dp 训练模型。它仅支持 Zero 阶段1和阶段2。 - Gemini 插件: 它包装了 Gemini,Gemini 实现了基于Chunk内存管理和异构内存管理的 Zero-3。
- Hybrid Parallel 插件: 它为Shardformer,流水线管理器,混合精度运算,TorchDDP以及Zero-1/Zero-2功能提供了一个统一且简洁的接口。使用该插件可以简单高效地实现transformer模型在张量并行,流水线并行以及数据并行(DDP, Zero)间任意组合并行训练策略,同时支持多种训练速度和内存的优化工具。有关这些训练策略和优化工具的具体信息将在下一章中阐述。
更多插件即将推出。
插件选择
- Torch DDP 插件: 适用于参数少于 20 亿的模型(例如 Bert-3m、GPT2-1.5b)。
- Torch FSDP 插件 / Low Level Zero 插件: 适用于参数少于 100 亿的模型(例如 GPTJ-6b、MegatronLM-8b)。
- Gemini 插件: 适合参数超过 100 亿的模型(例如 TuringNLG-17b),且跨节点带宽高、中小规模集群(千卡以下)的场景(例如 Llama2-70b)。
- Hybrid Parallel 插件: 适合参数超过 600 亿的模型、超长序列、超大词表等特殊模型,且跨节点带宽低、大规模集群(千卡以上)的场景(例如 GPT3-175b、Bloom-176b)。
插件
Low Level Zero 插件
该插件实现了 Zero-1 和 Zero-2(使用/不使用 CPU 卸载),使用reduce和gather来同步梯度和权重。
Zero-1 可以看作是 Torch DDP 更好的替代品,内存效率更高,速度更快。它可以很容易地用于混合并行。
Zero-2 不支持局部梯度累积。如果您坚持使用,虽然可以积累梯度,但不能降低通信成本。也就是说,同时使用流水线并行和 Zero-2 并不是一个好主意。
class
colossalai.booster.plugin.LowLevelZeroPlugin
- stage (int, optional) -- ZeRO stage. Defaults to 1.
- precision (str, optional) -- precision. Support 'fp16', 'bf16' and 'fp32'. Defaults to 'fp16'.
- initial_scale (float, optional) -- Initial scale used by DynamicGradScaler. Defaults to 2**32.
- min_scale (float, optional) -- Min scale used by DynamicGradScaler. Defaults to 1.
- growth_factor (float, optional) -- growth_factor used by DynamicGradScaler. Defaults to 2.
- backoff_factor (float, optional) -- backoff_factor used by DynamicGradScaler. Defaults to 0.5.
- growth_interval (float, optional) -- growth_interval used by DynamicGradScaler. Defaults to 1000.
- hysteresis (float, optional) -- hysteresis used by DynamicGradScaler. Defaults to 2.
- max_scale (int, optional) -- max_scale used by DynamicGradScaler. Defaults to 2**32.
- max_norm (float, optional) -- max_norm used for
clip_grad_norm. You should notice that you shall not do clip_grad_norm by yourself when using ZeRO DDP. The ZeRO optimizer will take care of clip_grad_norm. - norm_type (float, optional) -- norm_type used for
clip_grad_norm. - reduce_bucket_size_in_m (int, optional) -- grad reduce bucket size in M. Defaults to 12.
- communication_dtype (torch.dtype, optional) -- communication dtype. If not specified, the dtype of param will be used. Defaults to None.
- overlap_communication (bool, optional) -- whether to overlap communication and computation. Defaults to True.
- cpu_offload (bool, optional) -- whether to offload grad, master weight and optimizer state to cpu. Defaults to False.
- verbose (bool, optional) -- verbose mode. Debug info including grad overflow will be printed. Defaults to False.
- use_fp8 (bool, optional) -- Whether to enable fp8 mixed precision training. Defaults to False.
- fp8_communication (bool, optional) -- Whether to enable fp8 communication. Defaults to False.
- extra_dp_size (int, optional) -- The number of extra data parallel groups. Defaults to 1.
Plugin for low level zero.
from colossalai.booster import Booster
from colossalai.booster.plugin import LowLevelZeroPlugin
model, train_dataset, optimizer, criterion = ...
plugin = LowLevelZeroPlugin()
train_dataloader = plugin.prepare_dataloader(train_dataset, batch_size=8)
booster = Booster(plugin=plugin)
model, optimizer, train_dataloader, criterion = booster.boost(model, optimizer, train_dataloader, criterion)
function
add_lora_params_to_optimizer
我们已经测试了一些主流模型的兼容性,可能不支持以下模型:
timm.models.convit_base- dlrm and deepfm models in
torchrec
兼容性问题将在未来修复。
Gemini 插件
这个插件实现了基于Chunk内存管理和异构内存管理的 Zero-3。它可以训练大型模型而不会损失太多速度。它也不支持局部梯度累积。更多详细信息,请参阅 Gemini 文档.
class
colossalai.booster.plugin.GeminiPlugin
- chunk_config_dict (dict, optional) -- chunk configuration dictionary.
- chunk_init_device (torch.device, optional) -- device to initialize the chunk.
- placement_policy (str, optional) -- "static" and "auto". Defaults to "static".
- enable_gradient_accumulation (bool, optional) -- Whether to enable gradient accumulation. When set to True, gradient will be stored after doing backward pass. Defaults to False.
- shard_param_frac (float, optional) -- fraction of parameters to be sharded. Only for "static" placement.
If
shard_param_fracis 1.0, it's equal to zero-3. Ifshard_param_fracis 0.0, it's equal to zero-2. Defaults to 1.0. - offload_optim_frac (float, optional) -- fraction of optimizer states to be offloaded. Only for "static" placement.
If
shard_param_fracis 1.0 andoffload_optim_fracis 0.0, it's equal to old "cuda" placement. Defaults to 0.0. - offload_param_frac (float, optional) -- fraction of parameters to be offloaded. Only for "static" placement.
For efficiency, this argument is useful only when
shard_param_fracis 1.0 andoffload_optim_fracis 1.0. Ifshard_param_fracis 1.0,offload_optim_fracis 1.0 andoffload_param_fracis 1.0, it's equal to old "cpu" placement. When using static placement, we recommend users to tuneshard_param_fracfirst and thenoffload_optim_frac. Defaults to 0.0. - warmup_non_model_data_ratio (float, optional) -- ratio of expected non-model data memory during warmup. Only for "auto" placement. Defaults to 0.8.
- steady_cuda_cap_ratio (float, optional) -- ratio of allowed cuda capacity for model data during steady state. Only for "auto" placement. Defaults to 0.9.
- precision (str, optional) -- precision. Support 'fp16' and 'bf16'. Defaults to 'fp16'.
- master_weights (bool, optional) -- Whether to keep fp32 master parameter weights in optimizer. Defaults to True.
- pin_memory (bool, optional) -- use pin memory on CPU. Defaults to False.
- force_outputs_fp32 (bool, optional) -- force outputs are fp32. Defaults to False.
- strict_ddp_mode (bool, optional) -- use strict ddp mode (only use dp without other parallelism). Defaults to False.
- search_range_m (int, optional) -- chunk size searching range divided by 2^20. Defaults to 32.
- hidden_dim (int, optional) -- the hidden dimension of DNN. Users can provide this argument to speed up searching. If users do not know this argument before training, it is ok. We will use a default value 1024.
- min_chunk_size_m (float, optional) -- the minimum chunk size divided by 2^20. If the aggregate size of parameters is still smaller than the minimum chunk size, all parameters will be compacted into one small chunk.
- memstats (MemStats, optional) the memory statistics collector by a runtime memory tracer. --
- gpu_margin_mem_ratio (float, optional) -- The ratio of GPU remaining memory (after the first forward-backward)
which will be used when using hybrid CPU optimizer.
This argument is meaningless when
placement_policyofGeminiManageris not "auto". Defaults to 0.0. - initial_scale (float, optional) -- Initial scale used by DynamicGradScaler. Defaults to 2**16.
- min_scale (float, optional) -- Min scale used by DynamicGradScaler. Defaults to 1.
- growth_factor (float, optional) -- growth_factor used by DynamicGradScaler. Defaults to 2.
- backoff_factor (float, optional) -- backoff_factor used by DynamicGradScaler. Defaults to 0.5.
- growth_interval (float, optional) -- growth_interval used by DynamicGradScaler. Defaults to 1000.
- hysteresis (float, optional) -- hysteresis used by DynamicGradScaler. Defaults to 2.
- max_scale (int, optional) -- max_scale used by DynamicGradScaler. Defaults to 2**32.
- max_norm (float, optional) -- max_norm used for
clip_grad_norm. You should notice that you shall not do clip_grad_norm by yourself when using ZeRO DDP. The ZeRO optimizer will take care of clip_grad_norm. - norm_type (float, optional) -- norm_type used for
clip_grad_norm. - tp_size (int, optional) -- If 'tp_size' is set to be greater than 1, it means using tensor parallelism strategy, which is implemented in Shardformer, 'tp_size' determines the size of the tensor parallel process group. Default to 1.
- extra_dp_size (int, optional) -- If 'extra_dp_size' is set to be greater than 1, it means creating another group to run with a ddp-like strategy. Default to 1.
- enable_all_optimization (bool, optional) -- Whether to switch on all the optimizations supported by Shardformer. Currently all the optimization methods include fused normalization, flash attention and JIT. Defaults to False.
- enable_fused_normalization (bool, optional) -- Whether to switch on fused normalization in Shardformer. Defaults to False.
- enable_flash_attention (bool, optional) -- Whether to switch on flash attention in Shardformer. Defaults to False.
- enable_jit_fused (bool, optional) -- Whether to switch on JIT in Shardformer. Default to False.
- enable_sequence_parallelism (bool) -- Whether to turn on sequence parallelism in Shardformer. Defaults to False.
- use_fp8 (bool, optional) -- Whether to enable fp8 mixed precision training. Defaults to False.
- verbose (bool, optional) -- verbose mode. Debug info including chunk search result will be printed. Defaults to False.
- fp8_communication (bool, optional) -- Whether to enable fp8 communication. Defaults to False.
Plugin for Gemini.
from colossalai.booster import Booster
from colossalai.booster.plugin import GeminiPlugin
model, train_dataset, optimizer, criterion = ...
plugin = GeminiPlugin()
train_dataloader = plugin.prepare_dataloader(train_dataset, batch_size=8)
booster = Booster(plugin=plugin)
model, optimizer, train_dataloader, criterion = booster.boost(model, optimizer, train_dataloader, criterion)
Hybrid Parallel 插件
这个插件实现了多种并行训练策略和优化工具的组合。Hybrid Parallel插件支持的功能大致可以被分为以下四个部分:
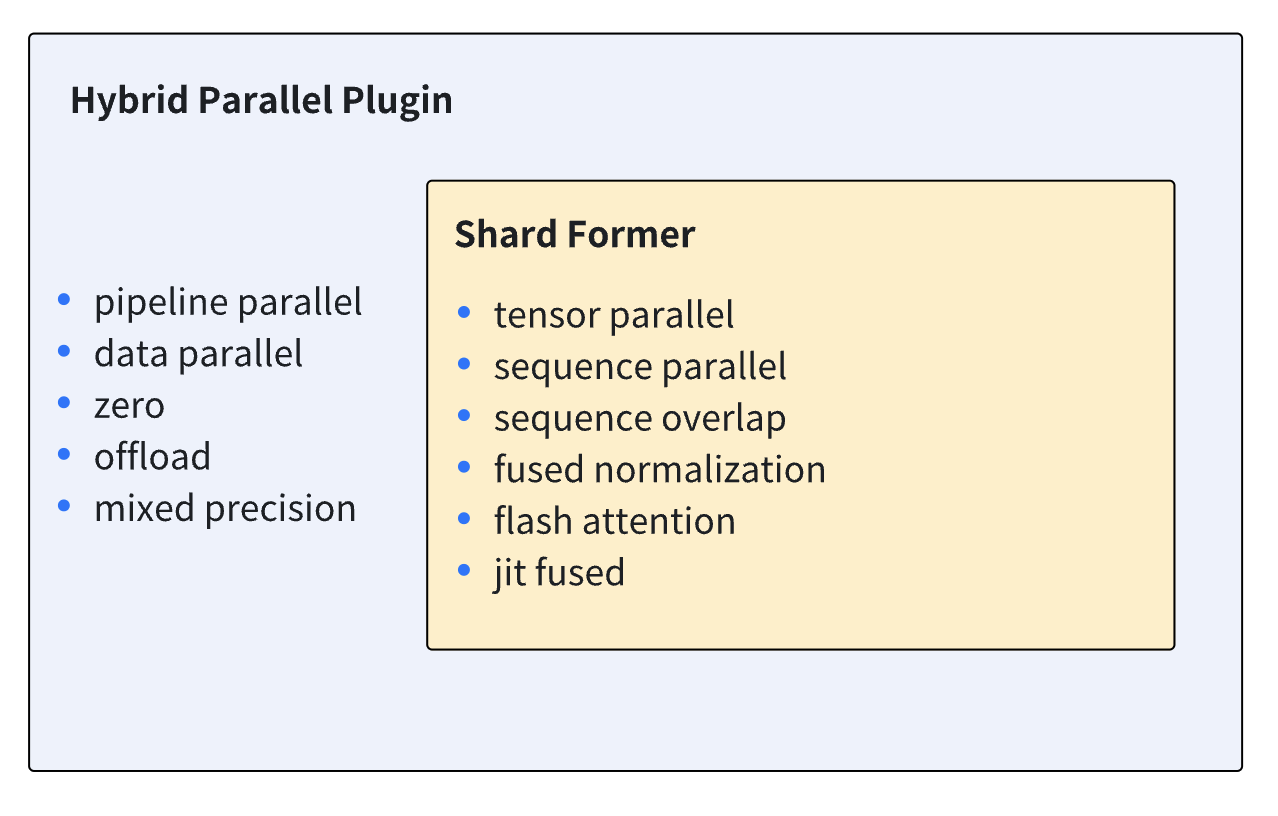
- Shardformer: Shardformer负责在张量并行以及流水线并行下切分模型的逻辑,以及前向/后向方法的重载,这个插件为Shardformer功能提供了一个简单易用的接口。与此同时,Shardformer还负责将包括fused normalization, flash attention (xformers), JIT和序列并行在内的各类优化工具融入重载后的前向/后向方法。更多关于Shardformer的信息请参考 Shardformer文档。下图展示了Shardformer与Hybrid Parallel插件所支持的功能。
混合精度训练:插件支持fp16/bf16的混合精度训练。更多关于混合精度训练的参数配置的详细信息请参考 混合精度训练文档。
Torch DDP: 当流水线并行和Zero不被使用的时候,插件会自动采用Pytorch DDP作为数据并行的策略。更多关于Torch DDP的参数配置的详细信息请参考 Pytorch DDP 文档。
Zero: 在初始化插件的时候,可以通过将
zero_stage参数设置为1或2来让插件采用Zero 1/2作为数据并行的策略。Zero 1可以和流水线并行策略同时使用, 而Zero 2则不可以和流水线并行策略同时使用。更多关于Zero的参数配置的详细信息请参考 Low Level Zero 插件.
⚠ 在使用该插件的时候, 只有支持Shardformer的部分Huggingface transformers模型才能够使用张量并行、流水线并行以及优化工具。Llama 1、Llama 2、OPT、Bloom、Bert以及GPT2等主流transformers模型均已支持Shardformer。
class
colossalai.booster.plugin.HybridParallelPlugin
- tp_size (int) -- The size of tensor parallelism. Tensor parallelism will not be used when tp_size is set to 1.
- pp_size (int) -- The number of pipeline stages in pipeline parallelism. Pipeline parallelism will not be used when pp_size is set to 1.
- sp_size (int) -- The size of sequence parallelism.
- precision (str, optional) -- Specifies the precision of parameters during training. Auto-mixied precision will be used when this argument is set to 'fp16' or 'bf16', otherwise model is trained with 'fp32'. Defaults to 'fp16'.
- zero_stage (int, optional) -- The stage of ZeRO for data parallelism. Can only be choosed from [0, 1, 2]. When set to 0, ZeRO will not be used. Defaults to 0.
- enable_all_optimization (bool, optional) -- Whether to switch on all the optimizations supported by Shardformer. Currently all the optimization methods include fused normalization, flash attention and JIT. Defaults to False.
- enable_fused_normalization (bool, optional) -- Whether to switch on fused normalization in Shardformer. Defaults to False.
- enable_flash_attention (bool, optional) -- Whether to switch on flash attention in Shardformer. Defaults to False.
- enable_jit_fused (bool, optional) -- Whether to switch on JIT in Shardformer. Default to False.
- enable_sequence_parallelism (bool) -- Whether to turn on sequence parallelism in Shardformer. Defaults to False.
- sequence_parallelism_mode (str) -- The Sequence parallelism mode. Can only be choosed from ["split_gather", "ring", "all_to_all"]. Defaults to "split_gather".
- parallel_output (bool) -- Whether to keep the output parallel when enabling tensor parallelism. Default to True.
- num_microbatches (int, optional) -- Number of microbatches when using pipeline parallelism. Defaults to None.
- microbatch_size (int, optional) -- Microbatch size when using pipeline parallelism.
Either
num_microbatchesormicrobatch_sizeshould be provided if using pipeline. Ifnum_microbatchesis provided, this will be ignored. Defaults to None. - initial_scale (float, optional) -- The initial loss scale of AMP. Defaults to 2**16.
- min_scale (float, optional) -- The minimum loss scale of AMP. Defaults to 1.
- growth_factor (float, optional) -- The multiplication factor for increasing loss scale when using AMP. Defaults to 2.
- backoff_factor (float, optional) -- The multiplication factor for decreasing loss scale when using AMP. Defaults to 0.5.
- growth_interval (int, optional) -- The number of steps to increase loss scale when no overflow occurs when using AMP. Defaults to 1000.
- hysteresis (int, optional) -- The number of overflows before decreasing loss scale when using AMP. Defaults to 2.
- max_scale (float, optional) -- The maximum loss scale of AMP. Defaults to 2**32.
- max_norm (float, optional) -- Maximum norm for gradient clipping. Defaults to 0.
- broadcast_buffers (bool, optional) -- Whether to broadcast buffers in the beginning of training when using DDP. Defaults to True.
- ddp_bucket_cap_mb (int, optional) -- The bucket size in MB when using DDP. Defaults to 25.
- find_unused_parameters (bool, optional) -- Whether to find unused parameters when using DDP. Defaults to False.
- check_reduction (bool, optional) -- Whether to check reduction when using DDP. Defaults to False.
- gradient_as_bucket_view (bool, optional) -- Whether to use gradient as bucket view when using DDP. Defaults to False.
- static_graph (bool, optional) -- Whether to use static graph when using DDP. Defaults to False.
- zero_bucket_size_in_m (int, optional) -- Gradient reduce bucket size in million elements when using ZeRO. Defaults to 12.
- cpu_offload (bool, optional) -- Whether to open cpu_offload when using ZeRO. Defaults to False.
- communication_dtype (torch.dtype, optional) -- Communication dtype when using ZeRO. If not specified, the dtype of param will be used. Defaults to None.
- overlap_communication (bool, optional) -- Whether to overlap communication and computation when using ZeRO. Defaults to True.
- custom_policy (Policy, optional) -- Custom policy for Shardformer. Defaults to None.
- pp_style (str, optional) -- The style for pipeline parallelism. Defaults to '1f1b'.
- num_model_chunks (int, optional) -- The number of model chunks for interleaved pipeline parallelism. Defaults to 1.
- gradient_checkpoint_config (GradientCheckpointConfig, optional) -- Configuration for gradient checkpointing. Defaults to None.
- enable_metadata_cache (bool, optional) -- Whether to enable metadata cache for pipeline parallelism. Defaults to True.
- make_vocab_size_divisible_by (int, optional) -- it's used when padding the vocabulary size, to make it choose an faster kenel. Default to 64.
- fp8_communication (bool, optional) -- Whether to enable fp8 communication. Defaults to False.
- use_fp8 (bool, optional) -- Whether to enable fp8 mixed precision training. Defaults to False.
- overlap_p2p (bool, optional) -- Whether to overlap the p2p communication in pipeline parallelism
- inner_ring_size (int, optional) -- The inner ring size of 2D Ring Attention when sp mode is "ring_attn". It's advisable to not tune this (especially in single-node settings) and let it be heuristically set based on topology by default.
Plugin for Hybrid Parallel Training. Tensor parallel, pipeline parallel and data parallel(DDP/ZeRO) can be picked and combined in this plugin. The size of tp and pp should be passed in by user, then the size of dp is automatically calculated from dp_size = world_size / (tp_size * pp_size).
from colossalai.booster import Booster
from colossalai.booster.plugin import HybridParallelPlugin
model, train_dataset, optimizer, criterion = ...
plugin = HybridParallelPlugin(tp_size=2, pp_size=2)
train_dataloader = plugin.prepare_dataloader(train_dataset, batch_size=8)
booster = Booster(plugin=plugin)
model, optimizer, criterion, train_dataloader, _ = booster.boost(model, optimizer, criterion, train_dataloader)
function
prepare_dataloader
- dataset (torch.utils.data.Dataset) -- The dataset to be loaded.
- shuffle (bool, optional) -- Whether to shuffle the dataset. Defaults to False.
- seed (int, optional) -- Random worker seed for sampling, defaults to 1024.
add_sampler -- Whether to add
DistributedDataParallelSamplerto the dataset. Defaults to True. - drop_last (bool, optional) -- Set to True to drop the last incomplete batch, if the dataset size is not divisible by the batch size. If False and the size of dataset is not divisible by the batch size, then the last batch will be smaller, defaults to False.
- pin_memory (bool, optional) -- Whether to pin memory address in CPU memory. Defaults to False.
- num_workers (int, optional) -- Number of worker threads for this dataloader. Defaults to 0.
- kwargs (dict) -- optional parameters for
torch.utils.data.DataLoader, more details could be found in DataLoader.
Prepare a dataloader for distributed training. The dataloader will be wrapped by torch.utils.data.DataLoader and torch.utils.data.DistributedSampler.
Returns: [torch.utils.data.DataLoader`]: A DataLoader used for training or testing.
Torch DDP 插件
更多详细信息,请参阅 Pytorch 文档.
class
colossalai.booster.plugin.TorchDDPPlugin
- broadcast_buffers (bool, optional) -- Whether to broadcast buffers in the beginning of training. Defaults to True.
- bucket_cap_mb (int, optional) -- The bucket size in MB. Defaults to 25.
- find_unused_parameters (bool, optional) -- Whether to find unused parameters. Defaults to False.
- check_reduction (bool, optional) -- Whether to check reduction. Defaults to False.
- gradient_as_bucket_view (bool, optional) -- Whether to use gradient as bucket view. Defaults to False.
- static_graph (bool, optional) -- Whether to use static graph. Defaults to False.
- fp8_communication (bool, optional) -- Whether to enable fp8 communication. Defaults to False.
Plugin for PyTorch DDP.
from colossalai.booster import Booster
from colossalai.booster.plugin import TorchDDPPlugin
model, train_dataset, optimizer, criterion = ...
plugin = TorchDDPPlugin()
train_dataloader = plugin.prepare_dataloader(train_dataset, batch_size=8)
booster = Booster(plugin=plugin)
model, optimizer, train_dataloader, criterion = booster.boost(model, optimizer, train_dataloader, criterion)
Torch FSDP 插件
⚠ 如果 torch 版本低于 1.12.0,此插件将不可用。
⚠ 该插件现在还不支持保存/加载分片的模型 checkpoint。
⚠ 该插件现在还不支持使用了multi params group的optimizer。
更多详细信息,请参阅 Pytorch 文档.
class
colossalai.booster.plugin.TorchFSDPPlugin
- See https --//pytorch.org/docs/stable/fsdp.html for details.
Plugin for PyTorch FSDP.
from colossalai.booster import Booster
from colossalai.booster.plugin import TorchFSDPPlugin
model, train_dataset, optimizer, criterion = ...
plugin = TorchFSDPPlugin()
train_dataloader = plugin.prepare_train_dataloader(train_dataset, batch_size=8)
booster = Booster(plugin=plugin)
model, optimizer, train_dataloader, criterion = booster.boost(model, optimizer, train_dataloader, criterion)