分布式训练
作者: Shenggui Li, Siqi Mai
什么是分布式系统?
分布式系统由多个软件组件组成,在多台机器上运行。例如,传统的数据库运行在一台机器上。随着数据量的爆发式增长,单台机器已经不能为企业提供理想的性能。特别是在双十一这样的网络狂欢节,网络流量会出乎意料的大。为了应对这种压力,现代高性能数据库被设计成在多台机器上运行,它们共同为用户提供高吞吐量和低延迟。
分布式系统的一个重要评价指标是可扩展性。例如,当我们在4台机器上运行一个应用程序时,我们自然希望该应用程序的运行速度能提高4倍。然而,由于通信开销和硬件性能的差异,很难实现线性提速。因此,当我们实现应用程序时,必须考虑如何使其更快。良好的设计和系统优化的算法可以帮助我们提供良好的性能。有时,甚至有可能实现线性和超线性提速。
为什么我们需要机器学习的分布式训练?
早在2012年,AlexNet 就赢得了ImageNet比赛的冠军,而它是在两张 GTX 580 3GB GPU 上训练的。今天,大多数出现在顶级人工智能会议上的模型都是在多个GPU上训练的。当研究人员和工程师开发人工智能模型时,分布式训练无疑是一种常见的做法。这一趋势背后有几个原因。
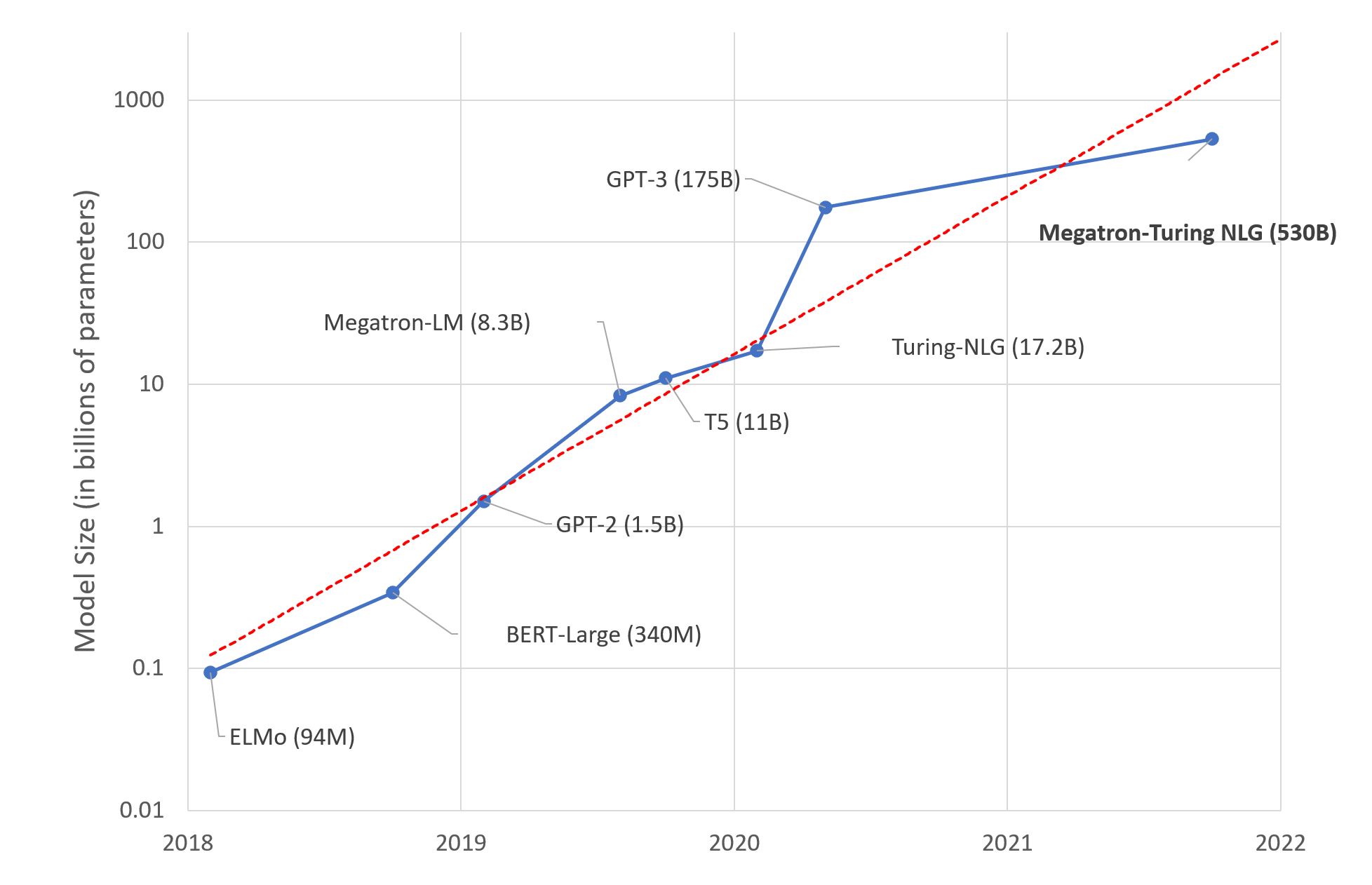
- 模型规模迅速增加。2015年的 ResNet50 有2000万的参数,
2018年的 BERT-Large有3.45亿的参数,2018年的
GPT-2
有15亿的参数,而2020年的 GPT-3 有1750亿个参数。很明显,模型规模随着时间的推移呈指数级增长。目前最大的模型已经超过了1000多亿个参数。而与较小的模型相比,超大型模型通常能提供更优越的性能。
图片来源: HuggingFace
- 数据集规模迅速增加。对于大多数机器学习开发者来说,MNIST 和 CIFAR10 数据集往往是他们训练模型的前几个数据集。然而,与著名的 ImageNet 数据集相比,这些数据集非常小。谷歌甚至有自己的(未公布的)JFT-300M 数据集,它有大约3亿张图片,这比 ImageNet-1k 数据集大了近300倍。
- 计算能力越来越强。随着半导体行业的进步,显卡变得越来越强大。由于核的数量增多,GPU是深度学习最常见的算力资源。从2012年的 K10 GPU 到2020年的 A100 GPU,计算能力已经增加了几百倍。这使我们能够更快地执行计算密集型任务,而深度学习正是这样一项任务。
如今,我们接触到的模型可能太大,以致于无法装入一个GPU,而数据集也可能大到足以在一个GPU上训练一百天。这时,只有用不同的并行化技术在多个GPU上训练我们的模型,我们才能完成并加快模型训练,以追求在合理的时间内获得想要的结果。
分布式训练的基本概念
分布式训练需要多台机器/GPU。在训练期间,这些设备之间会有通信。为了更好地理解分布式训练,有几个重要的术语需要我们了解清楚。
- host: 主机(host)是通信网络中的主要设备。在初始化分布式环境时,经常需要它作为一个参数。
- port: 这里的端口(port)主要是指主机上用于通信的主端口。
- rank: 在网络中赋予设备的唯一ID。
- world size: 网络中设备的数量。
- process group: 进程组(process group)是一个通信网络,包括设备的一个子集。总是有一个默认的进程组,它包含所有的设备。一个子集的设备可以形成一个进程组,以便它们只在组内的设备之间进行通信。
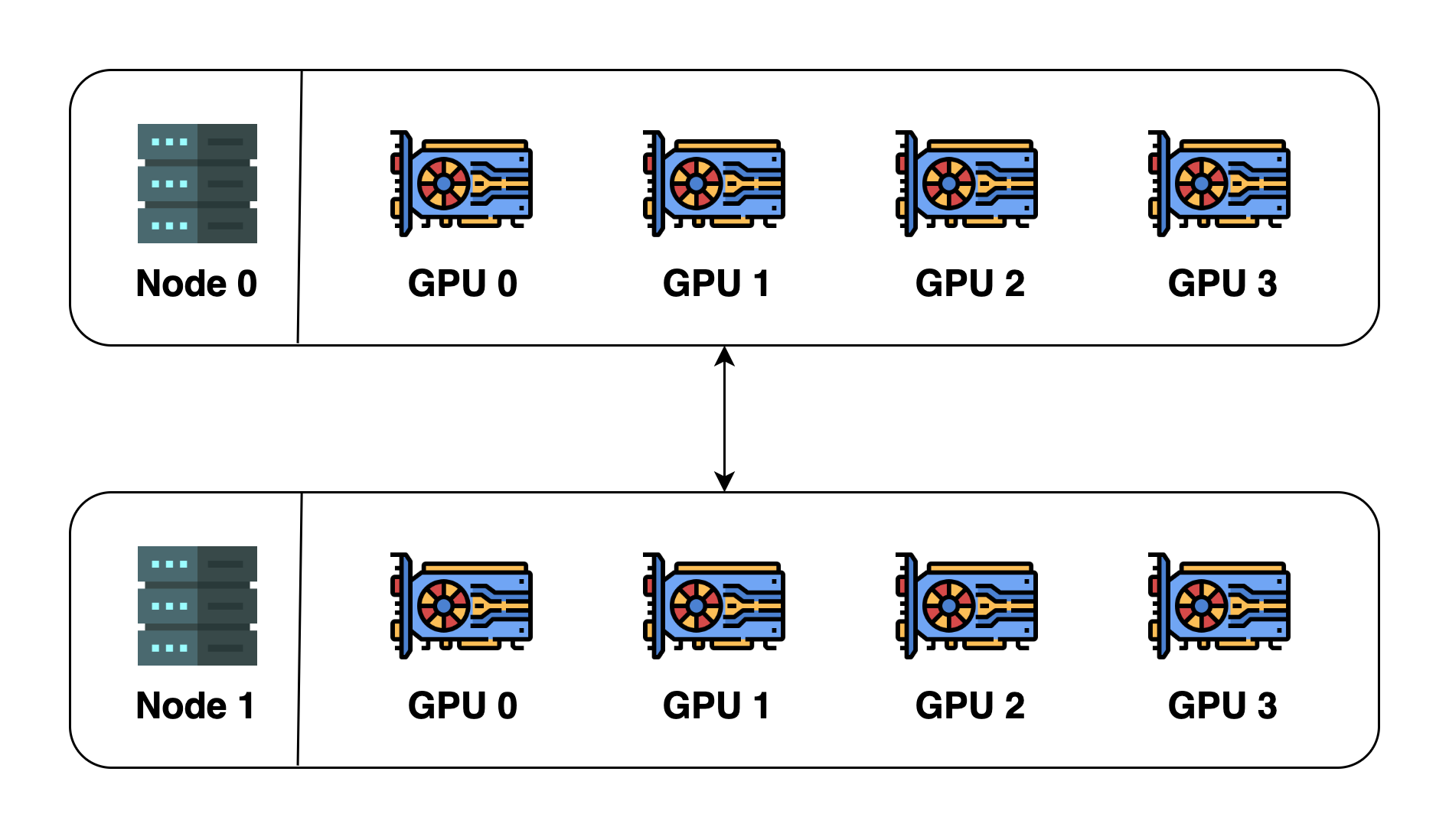
为了说明这些概念,让我们假设我们有2台机器(也称为节点),每台机器有4个 GPU。当我们在这两台机器上初始化分布式环境时,我们基本上启动了8个进程(每台机器上有4个进程),每个进程被绑定到一个 GPU 上。
在初始化分布式环境之前,我们需要指定主机(主地址)和端口(主端口)。在这个例子中,我们可以让主机为节点0,端口为一个数字,如29500。所有的8个进程将寻找地址和端口并相互连接,默认的进程组将被创建。默认进程组的 world size 为8,细节如下。
| process ID | rank | Node index | GPU index |
|---|---|---|---|
| 0 | 0 | 0 | 0 |
| 1 | 1 | 0 | 1 |
| 2 | 2 | 0 | 2 |
| 3 | 3 | 0 | 3 |
| 4 | 4 | 1 | 0 |
| 5 | 5 | 1 | 1 |
| 6 | 6 | 1 | 2 |
| 7 | 7 | 1 | 3 |
我们还可以创建一个新的进程组。这个新的进程组可以包含任何进程的子集。例如,我们可以创建一个只包含偶数进程的组:
| process ID | rank | Node index | GPU index |
|---|---|---|---|
| 0 | 0 | 0 | 0 |
| 2 | 1 | 0 | 2 |
| 4 | 2 | 1 | 0 |
| 6 | 3 | 1 | 2 |
请注意,rank 是相对于进程组而言的,一个进程在不同的进程组中可以有不同的 rank。最大的 rank 始终是 world size of the process group - 1。
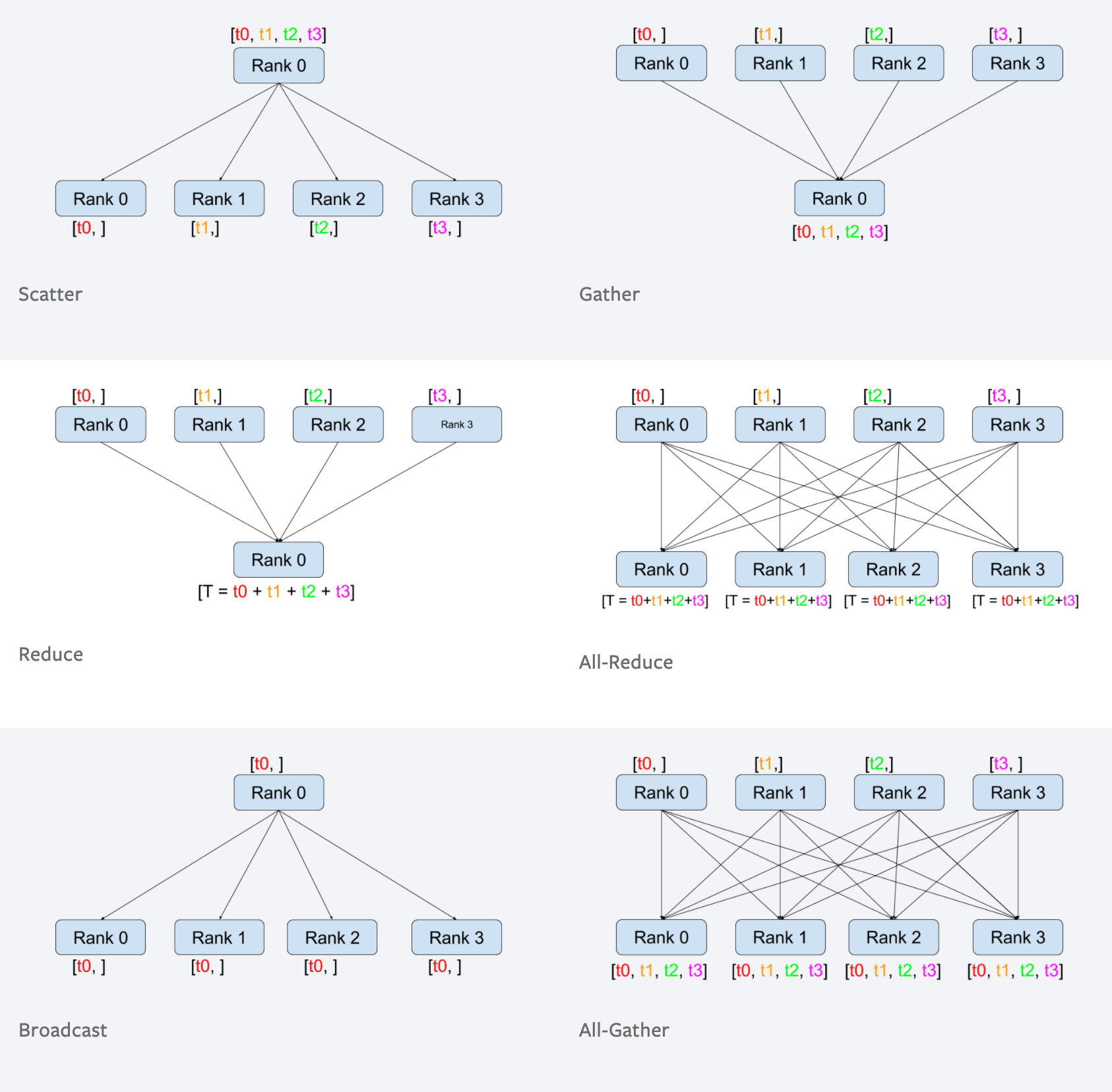
在进程组中,各进程可以通过两种方式进行通信。
- peer-to-peer: 一个进程向另一个进程发送数据。
- collective: 一组进程一起执行分散、聚集、all-reduce、广播等操作。