3D Tensor Parallelism
Author: Zhengda Bian, Yongbin Li
Prerequisite
Example Code
Related Paper
Introduction
The 3D tensor parallelism is an approach to parallelize the computation of neural models, hoping to obtain the optimal communication cost.
Let's still take a linear layer as an example. Given processors (necessary condition), e.g. , we split the input and weight into
where each and are stored at processor , as shown in the figure below.
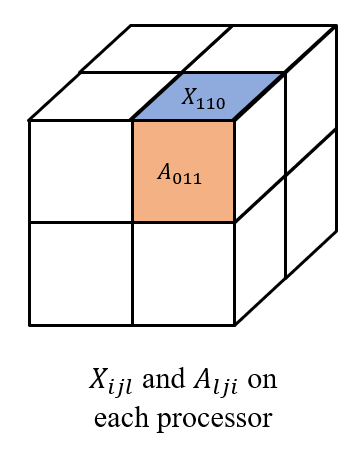
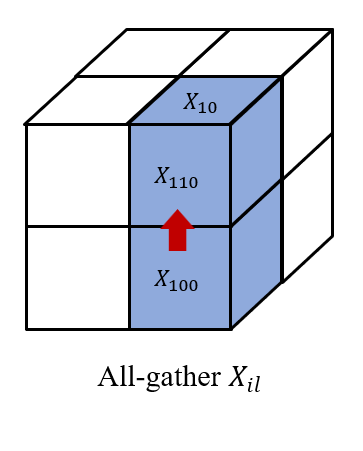
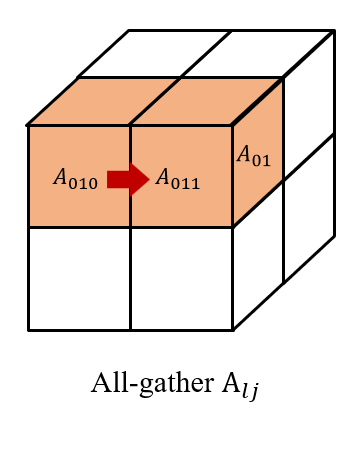
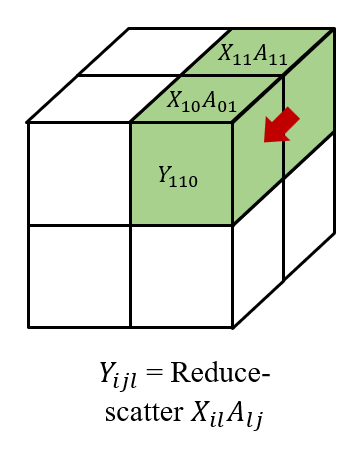
Then we all-gather across , as well as across . So, we have and on each processor to get . Finally, we reduce-scatter the results across to get , which forms
We also need to note that in the backward pass, we need to all-gather the gradient , and then reduce-scatter the gradient and .
Efficiency
Given processors, we present the theoretical computation and memory cost, as well as the communication cost based on the ring algorithm in both the forward and backward pass of 3D tensor parallelism.
| Computation | Memory (parameters) | Memory (activations) | Communication (bandwidth) | Communication (latency) |
|---|---|---|---|---|
Usage
Currently the newest version of ColossalAI doesn't support 3D tensor parallelism, but this feature will be integrated into Shardformer in future releases.
For more details about ideas and usages of Shardformer, please refer to Shardformer Doc.
For users of older version of ColossalAI, please refer to ColossalAI-Examples - 3D Tensor Parallelism.