将 MoE 整合进你的模型
作者: Haichen Huang, Yongbin Li
前置教程
相关论文
- Switch Transformers: Scaling to Trillion Parameter Models with Simple and Efficient Sparsity
- Go Wider Instead of Deeper
Introduction
自从Switch Transformer出现以来,人工智能社区发现专家混合 (MoE) 是一种扩大深度学习模型容量的有用技术。
Colossal-AI 提供了专为MoE模型设计的并行性的早期访问版本。Colossal-AI中MoE最突出的优势就是方便。我们的目标是帮助我们的用户轻松地将MoE与模型并行性和数据并行性结合起来。
但是,当前的实施现在有两个主要缺点。第一个缺点是它在大批量和长序列长度训练中效率低下。第二个缺点是与张量并行性不兼容。我们正在致力于系统优化,以克服训练效率问题。与张量并行的兼容性问题需要更多的适应,我们将在未来解决这个问题。
在这里,我们将介绍如何使用具有模型并行性和数据并行性的 MoE。
目录
在本教程中,我们将介绍:
我们提供示例, 详细介绍请参考 ColossalAI-Examples. 该示例使用 WideNet 作为基于 MoE 的模型的示例.
搭建MoE运行环境
在您的项目文件夹中,创建config.py文件。在该文件中,您可以指定希望用于训练模型的一些功能。为了启用 MoE,您需要在config.py中定义parallel字段,并指定moe的值。moe表示一组moe并行化训练组的并行大小。例如,moe设置为4,则4个进程将分配给4个连续的GPU,这4个进程组成一个moe模型并行组。每个进程只会得到一部分专家。增加mo e并行的大小将降低通信成本,但会增加每个GPU的计算成本和内存中activation的存储成本。总的数据并行的大小是自动检测的,默认情况下设置为GPU的数量。
MOE_MODEL_PARALLEL_SIZE = ...
parallel = dict(
moe=dict(size=MOE_MODEL_PARALLEL_SIZE)
)
如果MOE_MODEL_PARALLEL_SIZE = E,即设置专家的总数为E(E为一个常数)。在模型并行中,transformer编码器中前向部分的处理流程如下图所示。
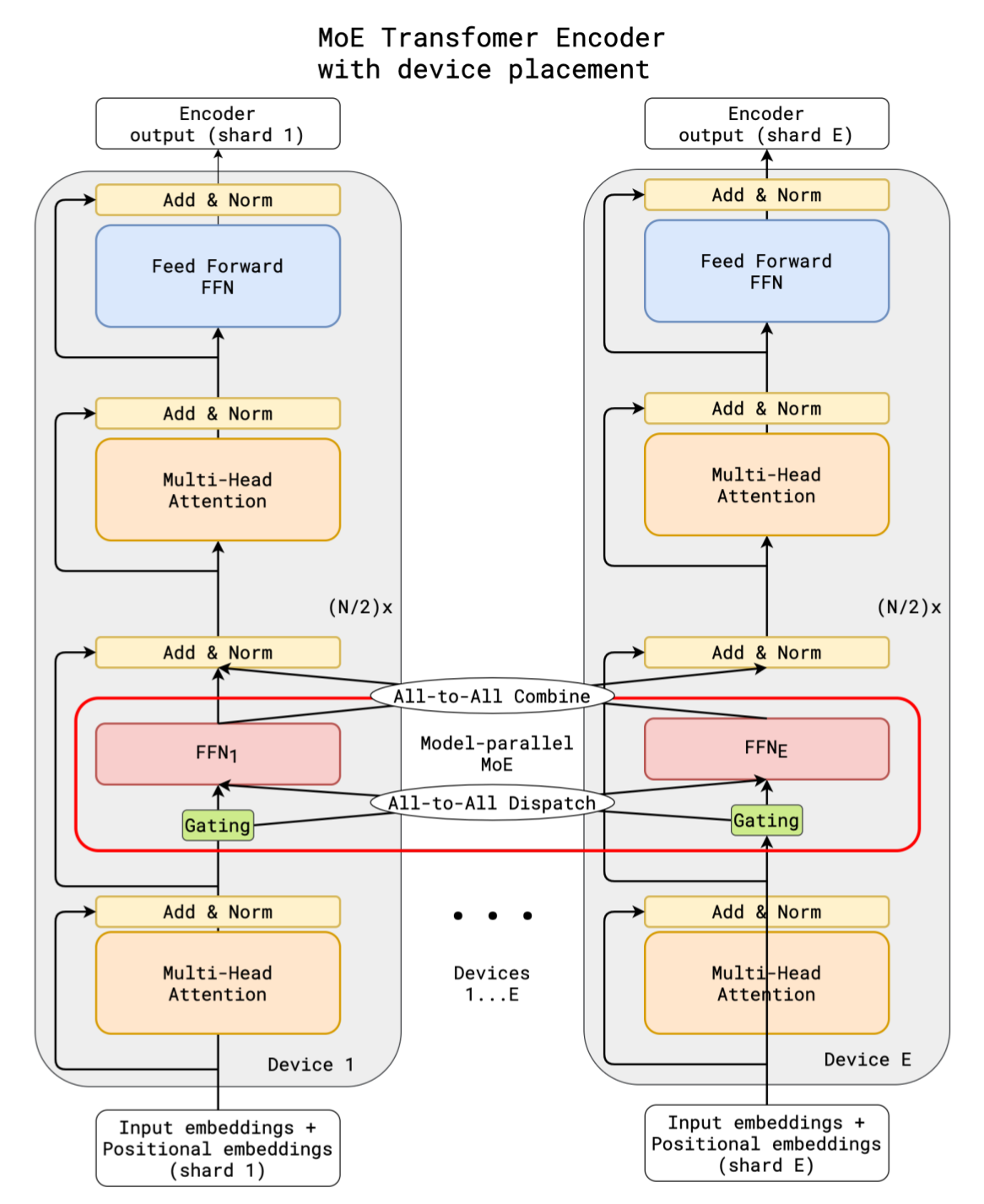
所有专家都分配给模型并行组中的GPU,每一个GPU只拥有一部分专家,原始数据并行组在反向传递的梯度处理期间不再适用于专家参数。所以我们创建了一个新的并行组,叫做moe数据并行组。当配置设置为WORLD_SIZE=4,MOE_MODEL_PARALLEL_SIZE=2时,两个并行组的区别如下图所示。
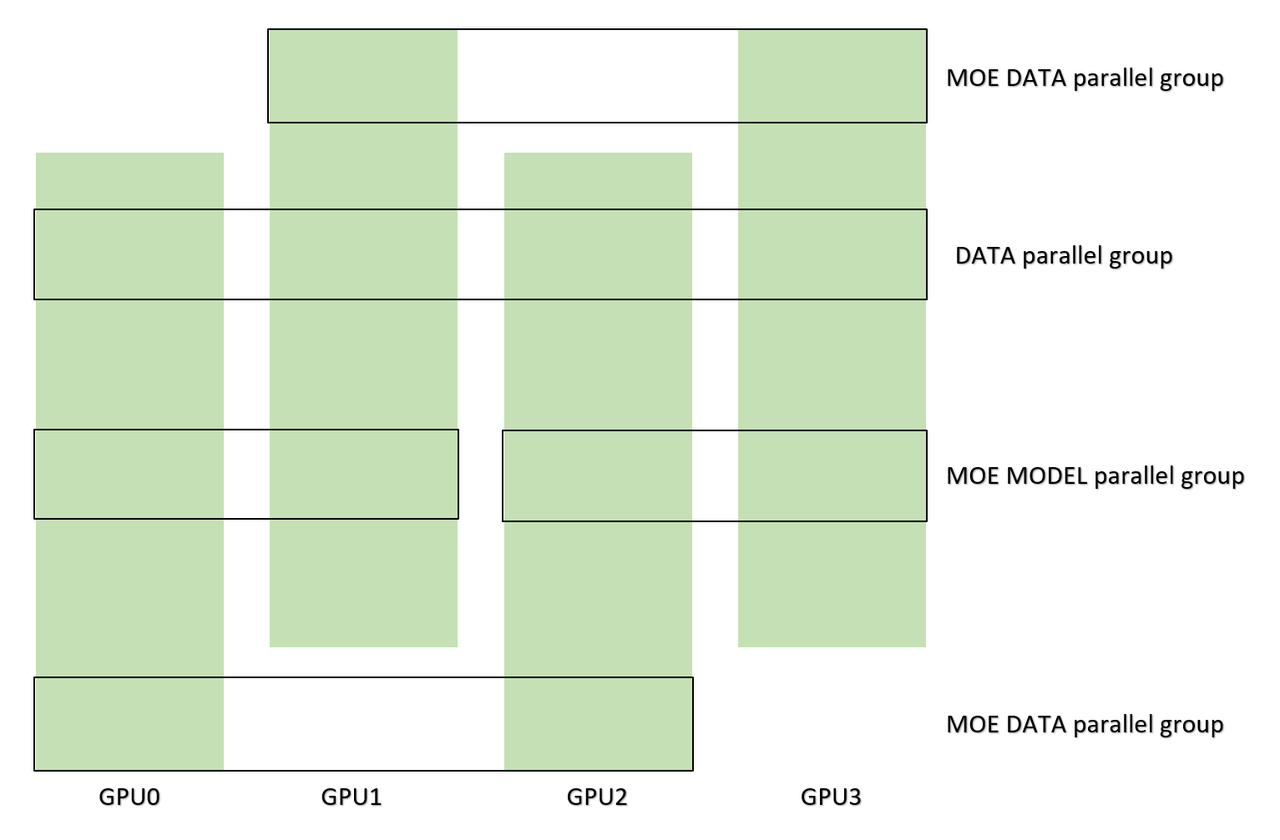
至于梯度处理,我们提供了MoeGradientHandler来all-reduce模型的每个参数。如果您使用colossalai.initialize函数创建您的训练引擎,MoE梯度处理程序将自动添加到您的引擎中。否则,你应该自己处理梯度。MoE运行环境的所有参数都保存在colossalai.global_variables.moe_env中。您可以访问您的配置参数来检查您的设置是否正确。
from colossalai.global_variables import moe_env
创建MoE层
您可以从colossalai.nn.moe创建MoE层。但在此之前,您应该为所有进程设置随机种子。
from colossalai.context.random import moe_set_seed
from model_zoo.moe.models import Widenet
moe_set_seed(42)
model = Widenet(num_experts=4, capacity_factor=1.2)
moe_set_seed 会为一个moe模型并行组中的不同进程设置不同的种子(这有助于在专家中初始化参数),创建一个专家实例和一个路由器实例,示例如下。
from colossalai.nn.layer.moe import Experts, MoeLayer, Top2Router, NormalNoiseGenerator
noisy_func = NormalNoiseGenerator(num_experts)
shared_router = Top2Router(capacity_factor,
noisy_func=noisy_func)
shared_experts = Experts(expert=VanillaFFN,
num_experts=num_experts,
**moe_mlp_args(
d_model=d_model,
d_ff=d_ff,
drop_rate=drop_rate
))
ffn=MoeLayer(dim_model=d_model, num_experts=num_experts,
router=shared_router, experts=shared_experts)
在Experts的初始化中,会自动计算每个GPU的本地expert数量,您只需指定每个专家的类型及其在初始化时使用的参数。此外,我们提供了Top1Router和Top2Router,您可以在colossalai.nn.layer.moe 找到它们。在创建experts和router的实例时,Moelayer只初始化了gate模块,类型的更多详细信息您可以参考我们的API文档和代码。
定义训练模型
使用colossalai中的colossalai.initialize函数为引擎添加梯度处理程序以处理 MoE模型的反向传播。在 colossalai.initialize 中,我们会自动创建一个MoeGradientHandler对象来处理梯度。您可以在colossal目录中找到有关MoeGradientHandler的更多信息。为了添加MoE的相关损失处理,损失函数应使用Moeloss封装,示例如下。
criterion = MoeLoss(
aux_weight=0.01,
loss_fn=nn.CrossEntropyLoss,
label_smoothing=0.1
)
最后,您只需使用 colossalai 中的trainer或engine进行训练即可。