Pipeline Parallel
Author: Guangyang Lu, Hongxin Liu, Yongbin Li, Mingyan Jiang
Prerequisite
Example Code
Related Paper
- Colossal-AI: A Unified Deep Learning System For Large-Scale Parallel Training
- Efficient Large-Scale Language Model Training on GPU Clusters Using Megatron-LM
- GPipe: Efficient Training of Giant Neural Networks using Pipeline Parallelism
Quick introduction
In this tutorial, you will learn how to use pipeline parallel. In Colossal-AI, we use 1F1B pipeline, introduced by Nvidia. In this case, ViT and Imagenet are too large to use. Therefore, here we use bert model and glue dataset as example.
Table Of Content
In this tutorial we will cover:
- Introduction of 1F1B pipeline.
- Usage of non-interleaved and interleaved schedule.
- Finetune Bert with pipeline.
Introduction of 1F1B pipeline
First of all, we will introduce you GPipe for your better understanding.
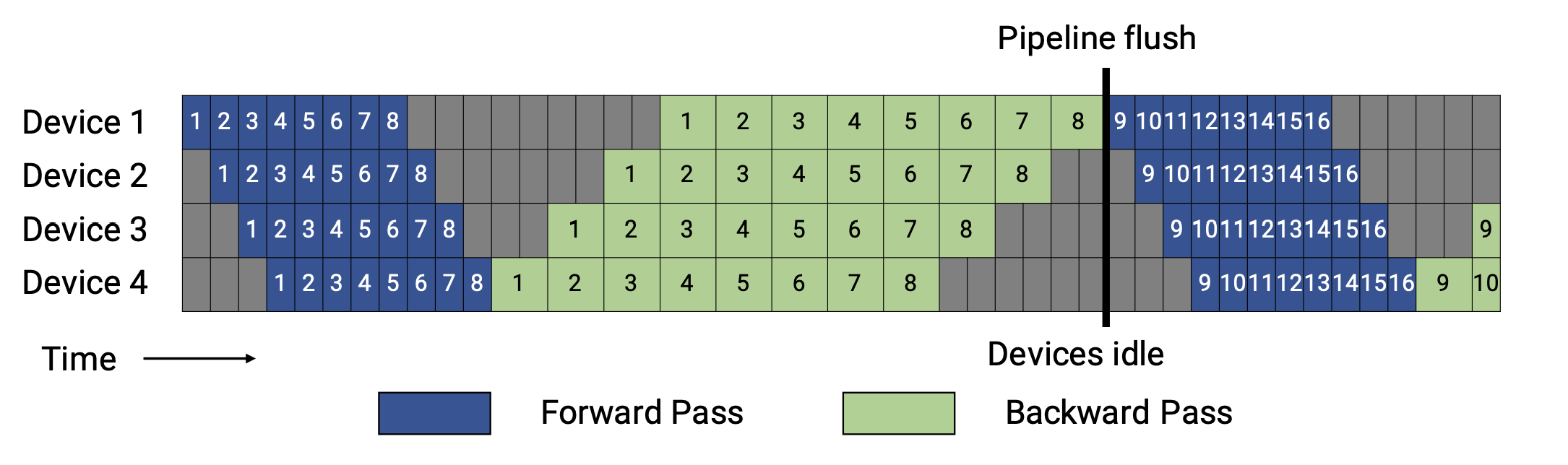
As you can see, for GPipe, only when the forward passes of all microbatches in a batch finish, the backward passes would be executed.
In general, 1F1B(one forward pass followed by one backward pass) is more efficient than GPipe(in memory or both memory and time). There are two schedules of 1F1B pipeline, the non-interleaved and the interleaved. The figures are shown below.
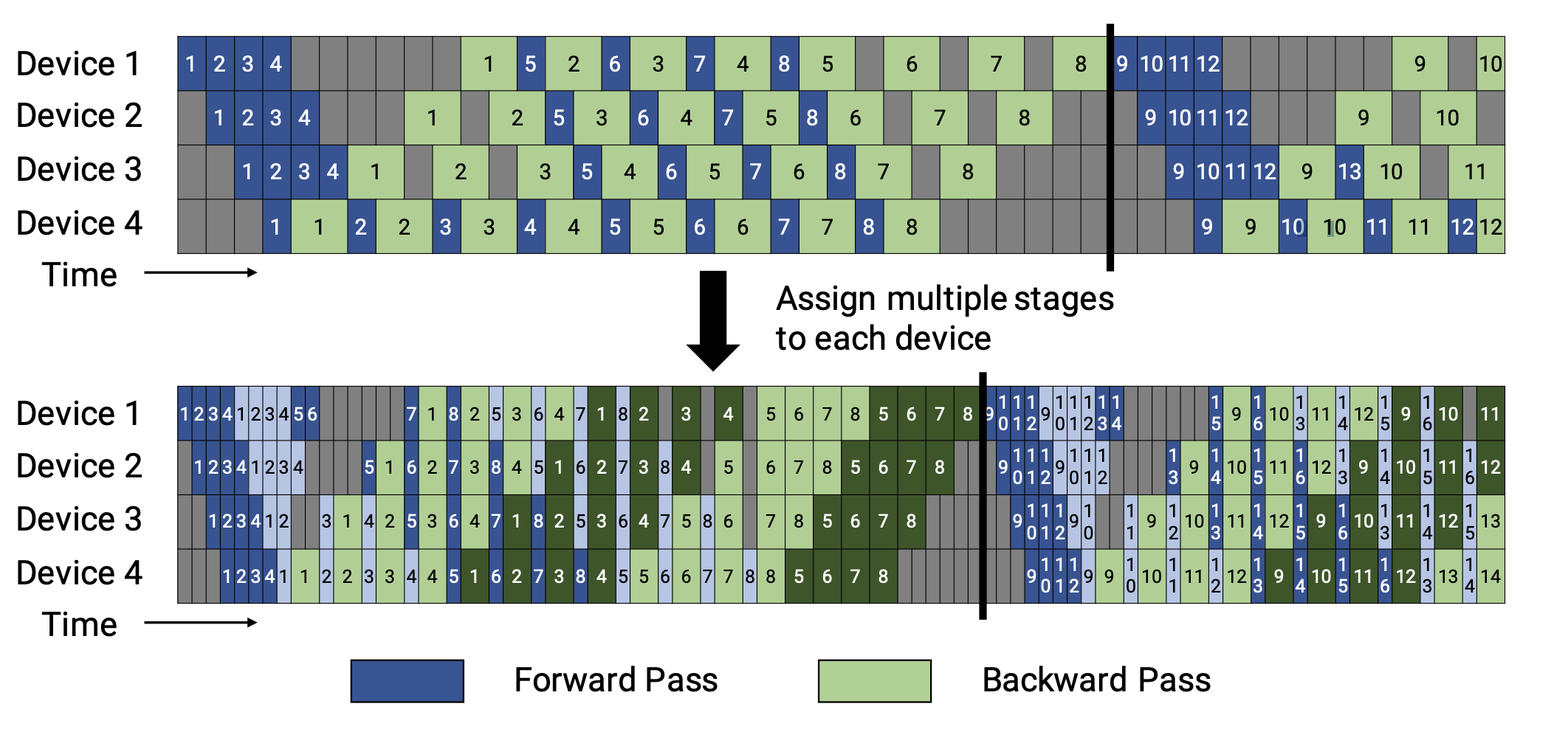
Non-interleaved Schedule
The non-interleaved schedule can be divided into three stages. The first stage is the warm-up stage, where workers perform differing numbers of forward passes. At the following stage, workers perform one forward pass followed by one backward pass. Workers will finish backward passes at the last stage.
This mode is more memory-efficient than GPipe. However, it would take the same time to finish a turn of passes as GPipe.
Interleaved Schedule
This schedule requires the number of microbatches to be an integer multiple of the stage of pipeline.
In this schedule, each device can perform computation for multiple subsets of layers(called a model chunk) instead of a single contiguous set of layers. i.e. Before device 1 had layer 1-4; device 2 had layer 5-8; and so on. But now device 1 has layer 1,2,9,10; device 2 has layer 3,4,11,12; and so on. With this scheme, each device in the pipeline is assigned multiple pipeline stages and each pipeline stage has less computation.
This mode is both memory-efficient and time-efficient.
Colossal-AI's Implementation
In Colossal-AI, pipeline parallelism relies on the scheduler and Shardformer. We provide both non-interleaved (OneForwardOneBackwardSchedule) and interleaved (InterleavedSchedule) schedules. While Shardformer implements layer splitting for models and replaces the forward function of the model to make it compatible with the scheduler.
In Colossal-AI, the HybridParallelPlugin encapsulates pipeline execution strategies. It manages pipeline parallel communication groups and a scheduler. When boosting the model with this plugin, the model's layers are split by calling the shardformer.optimize function, and then execute_pipeline is called to execute the model in segments using OneForwardOneBackwardSchedule which is default scheduler used in HybridParallelPlugin, and InterleavedSchedule will be integrated later.
You can customize your parallel strategy by setting parameters for the HybridParallelPlugin.
For more usage details, please refer to the documentation for HybridParallelPlugin.
Fine-tune Bert with pipeline
First, we define the necessary training components, including model, dataloader, optimizer, lr_scheduler, criterion:
import argparse
from typing import Callable, List, Union
import torch
import torch.nn as nn
from data import GLUEDataBuilder
from torch.optim import Adam, Optimizer
from torch.optim.lr_scheduler import _LRScheduler as LRScheduler
from torch.utils.data import DataLoader
from tqdm import tqdm
from transformers import (
AlbertForSequenceClassification,
AutoConfig,
BertForSequenceClassification,
get_linear_schedule_with_warmup,
)
import colossalai
from colossalai.booster import Booster
from colossalai.booster.plugin import HybridParallelPlugin
from colossalai.cluster import DistCoordinator
from colossalai.nn.optimizer import HybridAdam
# Define some config
NUM_EPOCHS = 3
BATCH_SIZE = 32
LEARNING_RATE = 2.4e-5
WEIGHT_DECAY = 0.01
WARMUP_FRACTION = 0.1
coordinator = DistCoordinator()
def move_to_cuda(batch):
return {k: v.cuda() for k, v in batch.items()}
# Define 'criterion' function with two inputs, which will be passed to 'execute_pipeline'.
def _criterion(outputs, inputs):
return outputs.loss
# Define optimizer
lr = LEARNING_RATE
no_decay = ["bias", "LayerNorm.weight"]
optimizer_grouped_parameters = [
{
"params": [p for n, p in model.named_parameters() if not any(nd in n for nd in no_decay)],
"weight_decay": WEIGHT_DECAY,
},
{
"params": [p for n, p in model.named_parameters() if any(nd in n for nd in no_decay)],
"weight_decay": 0.0,
},
]
optimizer = HybridAdam(optimizer_grouped_parameters, lr=lr, eps=1e-8)
# Define lr_scheduler
total_steps = len(train_dataloader) * NUM_EPOCHS
num_warmup_steps = int(WARMUP_FRACTION * total_steps)
lr_scheduler = get_linear_schedule_with_warmup(
optimizer,
num_warmup_steps=num_warmup_steps,
num_training_steps=total_steps,
)
# Define Bert model
model = BertForSequenceClassification.from_pretrained("bert-base-uncased", config=cfg).cuda()
# Define a dataloader
data_builder = GLUEDataBuilder(model_name,
plugin,
args.task,
train_batch_size=BATCH_SIZE,
eval_batch_size=BATCH_SIZE)
train_dataloader = data_builder.train_dataloader()
Define a booster with the HybridParallelPlugin.
plugin = HybridParallelPlugin(tp_size=1,
pp_size=2,
num_microbatches=None,
microbatch_size=1,
enable_all_optimization=True,
zero_stage=1,
precision='fp16',
initial_scale=1)
booster = Booster(plugin=plugin)
Boost these train components with the booster created.
model, optimizer, _criterion, _, lr_scheduler = booster.boost(model,
optimizer,
criterion=_criterion,
lr_scheduler=lr_scheduler)
Train the model at last.
# Define a train function
def train_epoch(epoch: int, model: nn.Module, optimizer: Optimizer, _criterion: Callable, lr_scheduler: LRScheduler,
train_dataloader: DataLoader, booster: Booster, coordinator: DistCoordinator):
is_pp_last_stage = booster.plugin.stage_manager.is_last_stage()
total_step = len(train_dataloader)
model.train()
optimizer.zero_grad()
# convert train_dataloader to a iterator
train_dataloader_iter = iter(train_dataloader)
with tqdm(range(total_step),
desc=f'Epoch [{epoch + 1}/{NUM_EPOCHS}]',
disable=not (is_pp_last_stage)) as pbar:
# Forward pass
for _ in pbar:
outputs = booster.execute_pipeline(train_dataloader_iter,
model,
_criterion,
optimizer,
return_loss=True)
# Backward and optimize
if is_pp_last_stage:
loss = outputs['loss']
pbar.set_postfix({'loss': loss.item()})
optimizer.step()
optimizer.zero_grad()
lr_scheduler.step()
# Train model
for epoch in range(NUM_EPOCHS):
train_epoch(epoch, model, optimizer, _criterion, lr_scheduler, train_dataloader, booster, coordinator)
We use 2 pipeline stages and the micro batches is 1. (these parameters can be configured to an appropriate value)