Booster Plugins
Author: Hongxin Liu, Baizhou Zhang, Pengtai Xu
Prerequisite:
Introduction
As mentioned in Booster API, we can use booster plugins to customize the parallel training. In this tutorial, we will introduce how to use booster plugins.
We currently provide the following plugins:
- Torch DDP Plugin: It is a wrapper of
torch.nn.parallel.DistributedDataParalleland can be used to train models with data parallelism. - Torch FSDP Plugin: It is a wrapper of
torch.distributed.fsdp.FullyShardedDataParalleland can be used to train models with zero-dp. - Low Level Zero Plugin: It wraps the
colossalai.zero.low_level.LowLevelZeroOptimizerand can be used to train models with zero-dp. It only supports zero stage-1 and stage-2. - Gemini Plugin: It wraps the Gemini which implements Zero-3 with chunk-based and heterogeneous memory management.
- Hybrid Parallel Plugin: It provides a tidy interface that integrates the power of Shardformer, pipeline manager, mixied precision training, TorchDDP and Zero stage 1/2 feature. With this plugin, transformer models can be easily trained with any combination of tensor parallel, pipeline parallel and data parallel (DDP/Zero) efficiently, along with various kinds of optimization tools for acceleration and memory saving. Detailed information about supported parallel strategies and optimization tools is explained in the section below.
More plugins are coming soon.
Choosing Your Plugin
Generally only one plugin is used to train a model. Our recommended use case for each plugin is as follows.
- Torch DDP Plugin: It is suitable for models with less than 2 billion parameters (e.g. Bert-3m, GPT2-1.5b).
- Torch FSDP Plugin / Low Level Zero Plugin: It is suitable for models with less than 10 billion parameters (e.g. GPTJ-6b, MegatronLM-8b).
- Gemini Plugin: It is suitable for models with more than 10 billion parameters (e.g. TuringNLG-17b) and is ideal for scenarios with high cross-node bandwidth and medium to small-scale clusters (below a thousand cards) (e.g. Llama2-70b).
- Hybrid Parallel Plugin: It is suitable for models with more than 60 billion parameters, or special models such as those with exceptionally long sequences, very large vocabularies, and is best suited for scenarios with low cross-node bandwidth and large-scale clusters (a thousand cards or more) (e.g. GPT3-175b, Bloom-176b).
Plugins
Low Level Zero Plugin
This plugin implements Zero-1 and Zero-2 (w/wo CPU offload), using reduce and gather to synchronize gradients and weights.
Zero-1 can be regarded as a better substitute of Torch DDP, which is more memory efficient and faster. It can be easily used in hybrid parallelism.
Zero-2 does not support local gradient accumulation. Though you can accumulate gradient if you insist, it cannot reduce communication cost. That is to say, it's not a good idea to use Zero-2 with pipeline parallelism.
class
colossalai.booster.plugin.LowLevelZeroPlugin
- stage (int, optional) -- ZeRO stage. Defaults to 1.
- precision (str, optional) -- precision. Support 'fp16', 'bf16' and 'fp32'. Defaults to 'fp16'.
- initial_scale (float, optional) -- Initial scale used by DynamicGradScaler. Defaults to 2**32.
- min_scale (float, optional) -- Min scale used by DynamicGradScaler. Defaults to 1.
- growth_factor (float, optional) -- growth_factor used by DynamicGradScaler. Defaults to 2.
- backoff_factor (float, optional) -- backoff_factor used by DynamicGradScaler. Defaults to 0.5.
- growth_interval (float, optional) -- growth_interval used by DynamicGradScaler. Defaults to 1000.
- hysteresis (float, optional) -- hysteresis used by DynamicGradScaler. Defaults to 2.
- max_scale (int, optional) -- max_scale used by DynamicGradScaler. Defaults to 2**32.
- max_norm (float, optional) -- max_norm used for
clip_grad_norm. You should notice that you shall not do clip_grad_norm by yourself when using ZeRO DDP. The ZeRO optimizer will take care of clip_grad_norm. - norm_type (float, optional) -- norm_type used for
clip_grad_norm. - reduce_bucket_size_in_m (int, optional) -- grad reduce bucket size in M. Defaults to 12.
- communication_dtype (torch.dtype, optional) -- communication dtype. If not specified, the dtype of param will be used. Defaults to None.
- overlap_communication (bool, optional) -- whether to overlap communication and computation. Defaults to True.
- cpu_offload (bool, optional) -- whether to offload grad, master weight and optimizer state to cpu. Defaults to False.
- verbose (bool, optional) -- verbose mode. Debug info including grad overflow will be printed. Defaults to False.
- use_fp8 (bool, optional) -- Whether to enable fp8 mixed precision training. Defaults to False.
- fp8_communication (bool, optional) -- Whether to enable fp8 communication. Defaults to False.
- extra_dp_size (int, optional) -- The number of extra data parallel groups. Defaults to 1.
Plugin for low level zero.
from colossalai.booster import Booster
from colossalai.booster.plugin import LowLevelZeroPlugin
model, train_dataset, optimizer, criterion = ...
plugin = LowLevelZeroPlugin()
train_dataloader = plugin.prepare_dataloader(train_dataset, batch_size=8)
booster = Booster(plugin=plugin)
model, optimizer, train_dataloader, criterion = booster.boost(model, optimizer, train_dataloader, criterion)
function
add_lora_params_to_optimizer
We've tested compatibility on some famous models, following models may not be supported:
timm.models.convit_base- dlrm and deepfm models in
torchrec
Compatibility problems will be fixed in the future.
Gemini Plugin
This plugin implements Zero-3 with chunk-based and heterogeneous memory management. It can train large models without much loss in speed. It also does not support local gradient accumulation. More details can be found in Gemini Doc.
class
colossalai.booster.plugin.GeminiPlugin
- chunk_config_dict (dict, optional) -- chunk configuration dictionary.
- chunk_init_device (torch.device, optional) -- device to initialize the chunk.
- placement_policy (str, optional) -- "static" and "auto". Defaults to "static".
- enable_gradient_accumulation (bool, optional) -- Whether to enable gradient accumulation. When set to True, gradient will be stored after doing backward pass. Defaults to False.
- shard_param_frac (float, optional) -- fraction of parameters to be sharded. Only for "static" placement.
If
shard_param_fracis 1.0, it's equal to zero-3. Ifshard_param_fracis 0.0, it's equal to zero-2. Defaults to 1.0. - offload_optim_frac (float, optional) -- fraction of optimizer states to be offloaded. Only for "static" placement.
If
shard_param_fracis 1.0 andoffload_optim_fracis 0.0, it's equal to old "cuda" placement. Defaults to 0.0. - offload_param_frac (float, optional) -- fraction of parameters to be offloaded. Only for "static" placement.
For efficiency, this argument is useful only when
shard_param_fracis 1.0 andoffload_optim_fracis 1.0. Ifshard_param_fracis 1.0,offload_optim_fracis 1.0 andoffload_param_fracis 1.0, it's equal to old "cpu" placement. When using static placement, we recommend users to tuneshard_param_fracfirst and thenoffload_optim_frac. Defaults to 0.0. - warmup_non_model_data_ratio (float, optional) -- ratio of expected non-model data memory during warmup. Only for "auto" placement. Defaults to 0.8.
- steady_cuda_cap_ratio (float, optional) -- ratio of allowed cuda capacity for model data during steady state. Only for "auto" placement. Defaults to 0.9.
- precision (str, optional) -- precision. Support 'fp16' and 'bf16'. Defaults to 'fp16'.
- master_weights (bool, optional) -- Whether to keep fp32 master parameter weights in optimizer. Defaults to True.
- pin_memory (bool, optional) -- use pin memory on CPU. Defaults to False.
- force_outputs_fp32 (bool, optional) -- force outputs are fp32. Defaults to False.
- strict_ddp_mode (bool, optional) -- use strict ddp mode (only use dp without other parallelism). Defaults to False.
- search_range_m (int, optional) -- chunk size searching range divided by 2^20. Defaults to 32.
- hidden_dim (int, optional) -- the hidden dimension of DNN. Users can provide this argument to speed up searching. If users do not know this argument before training, it is ok. We will use a default value 1024.
- min_chunk_size_m (float, optional) -- the minimum chunk size divided by 2^20. If the aggregate size of parameters is still smaller than the minimum chunk size, all parameters will be compacted into one small chunk.
- memstats (MemStats, optional) the memory statistics collector by a runtime memory tracer. --
- gpu_margin_mem_ratio (float, optional) -- The ratio of GPU remaining memory (after the first forward-backward)
which will be used when using hybrid CPU optimizer.
This argument is meaningless when
placement_policyofGeminiManageris not "auto". Defaults to 0.0. - initial_scale (float, optional) -- Initial scale used by DynamicGradScaler. Defaults to 2**16.
- min_scale (float, optional) -- Min scale used by DynamicGradScaler. Defaults to 1.
- growth_factor (float, optional) -- growth_factor used by DynamicGradScaler. Defaults to 2.
- backoff_factor (float, optional) -- backoff_factor used by DynamicGradScaler. Defaults to 0.5.
- growth_interval (float, optional) -- growth_interval used by DynamicGradScaler. Defaults to 1000.
- hysteresis (float, optional) -- hysteresis used by DynamicGradScaler. Defaults to 2.
- max_scale (int, optional) -- max_scale used by DynamicGradScaler. Defaults to 2**32.
- max_norm (float, optional) -- max_norm used for
clip_grad_norm. You should notice that you shall not do clip_grad_norm by yourself when using ZeRO DDP. The ZeRO optimizer will take care of clip_grad_norm. - norm_type (float, optional) -- norm_type used for
clip_grad_norm. - tp_size (int, optional) -- If 'tp_size' is set to be greater than 1, it means using tensor parallelism strategy, which is implemented in Shardformer, 'tp_size' determines the size of the tensor parallel process group. Default to 1.
- extra_dp_size (int, optional) -- If 'extra_dp_size' is set to be greater than 1, it means creating another group to run with a ddp-like strategy. Default to 1.
- enable_all_optimization (bool, optional) -- Whether to switch on all the optimizations supported by Shardformer. Currently all the optimization methods include fused normalization, flash attention and JIT. Defaults to False.
- enable_fused_normalization (bool, optional) -- Whether to switch on fused normalization in Shardformer. Defaults to False.
- enable_flash_attention (bool, optional) -- Whether to switch on flash attention in Shardformer. Defaults to False.
- enable_jit_fused (bool, optional) -- Whether to switch on JIT in Shardformer. Default to False.
- enable_sequence_parallelism (bool) -- Whether to turn on sequence parallelism in Shardformer. Defaults to False.
- use_fp8 (bool, optional) -- Whether to enable fp8 mixed precision training. Defaults to False.
- verbose (bool, optional) -- verbose mode. Debug info including chunk search result will be printed. Defaults to False.
- fp8_communication (bool, optional) -- Whether to enable fp8 communication. Defaults to False.
Plugin for Gemini.
from colossalai.booster import Booster
from colossalai.booster.plugin import GeminiPlugin
model, train_dataset, optimizer, criterion = ...
plugin = GeminiPlugin()
train_dataloader = plugin.prepare_dataloader(train_dataset, batch_size=8)
booster = Booster(plugin=plugin)
model, optimizer, train_dataloader, criterion = booster.boost(model, optimizer, train_dataloader, criterion)
Hybrid Parallel Plugin
This plugin implements the combination of various parallel training strategies and optimization tools. The features of HybridParallelPlugin can be generally divided into four parts:
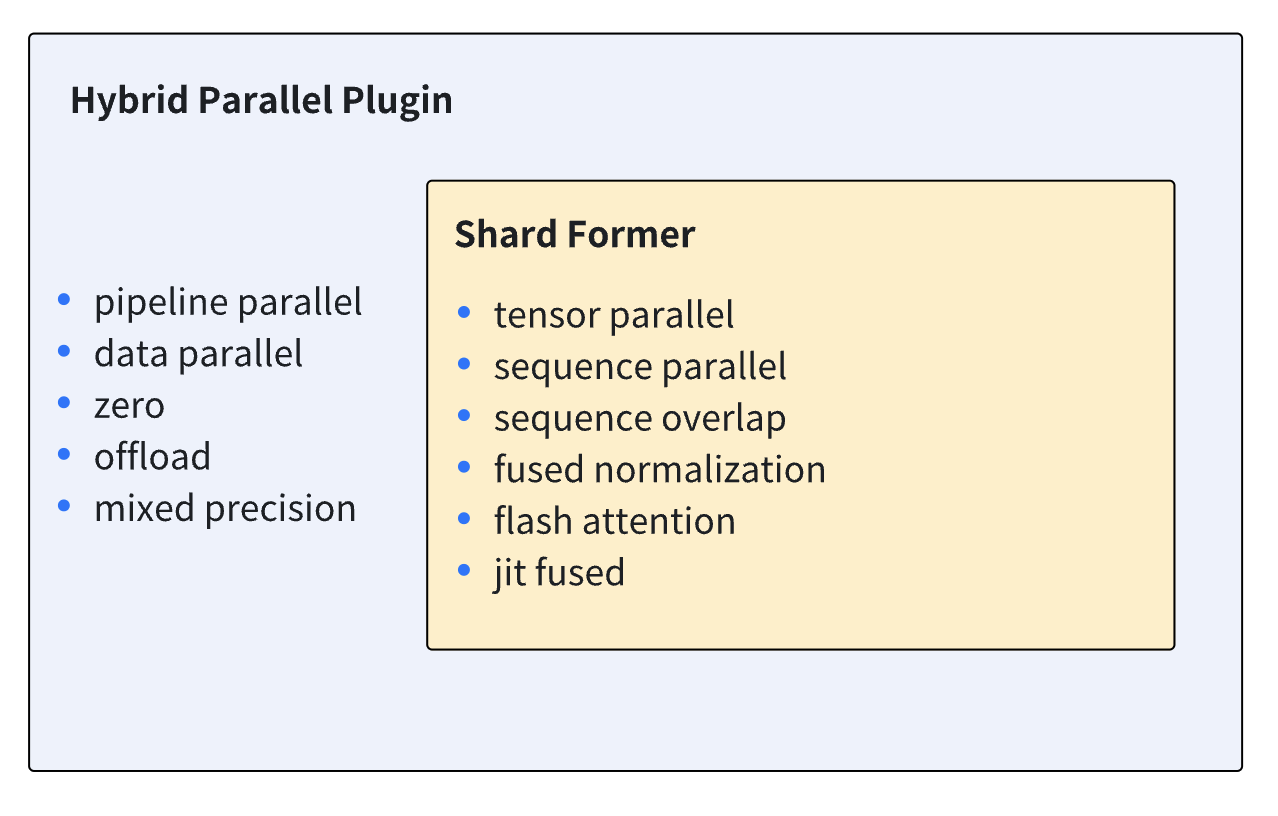
- Shardformer: This plugin provides an entrance to Shardformer, which controls model sharding under tensor parallel and pipeline parallel setting. Shardformer also overloads the logic of model's forward/backward process to ensure the smooth working of tp/pp. Also, optimization tools including fused normalization, flash attention (xformers), JIT and sequence parallel are injected into the overloaded forward/backward method by Shardformer. More details can be found in chapter Shardformer Doc. The diagram below shows the features supported by shardformer together with hybrid parallel plugin.
Mixed Precision Training: Support for fp16/bf16 mixed precision training. More details about its arguments configuration can be found in Mixed Precision Training Doc.
Torch DDP: This plugin will automatically adopt Pytorch DDP as data parallel strategy when pipeline parallel and Zero is not used. More details about its arguments configuration can be found in Pytorch DDP Docs.
Zero: This plugin can adopt Zero 1/2 as data parallel strategy through setting the
zero_stageargument as 1 or 2 when initializing plugin. Zero 1 is compatible with pipeline parallel strategy, while Zero 2 is not. More details about its argument configuration can be found in Low Level Zero Plugin.
⚠ When using this plugin, only the subset of Huggingface transformers supported by Shardformer are compatible with tensor parallel, pipeline parallel and optimization tools. Mainstream transformers such as Llama 1, Llama 2, OPT, Bloom, Bert and GPT2 etc. are all supported by Shardformer.
class
colossalai.booster.plugin.HybridParallelPlugin
- tp_size (int) -- The size of tensor parallelism. Tensor parallelism will not be used when tp_size is set to 1.
- pp_size (int) -- The number of pipeline stages in pipeline parallelism. Pipeline parallelism will not be used when pp_size is set to 1.
- sp_size (int) -- The size of sequence parallelism.
- precision (str, optional) -- Specifies the precision of parameters during training. Auto-mixied precision will be used when this argument is set to 'fp16' or 'bf16', otherwise model is trained with 'fp32'. Defaults to 'fp16'.
- zero_stage (int, optional) -- The stage of ZeRO for data parallelism. Can only be choosed from [0, 1, 2]. When set to 0, ZeRO will not be used. Defaults to 0.
- enable_all_optimization (bool, optional) -- Whether to switch on all the optimizations supported by Shardformer. Currently all the optimization methods include fused normalization, flash attention and JIT. Defaults to False.
- enable_fused_normalization (bool, optional) -- Whether to switch on fused normalization in Shardformer. Defaults to False.
- enable_flash_attention (bool, optional) -- Whether to switch on flash attention in Shardformer. Defaults to False.
- enable_jit_fused (bool, optional) -- Whether to switch on JIT in Shardformer. Default to False.
- enable_sequence_parallelism (bool) -- Whether to turn on sequence parallelism in Shardformer. Defaults to False.
- sequence_parallelism_mode (str) -- The Sequence parallelism mode. Can only be choosed from ["split_gather", "ring", "all_to_all"]. Defaults to "split_gather".
- parallel_output (bool) -- Whether to keep the output parallel when enabling tensor parallelism. Default to True.
- num_microbatches (int, optional) -- Number of microbatches when using pipeline parallelism. Defaults to None.
- microbatch_size (int, optional) -- Microbatch size when using pipeline parallelism.
Either
num_microbatchesormicrobatch_sizeshould be provided if using pipeline. Ifnum_microbatchesis provided, this will be ignored. Defaults to None. - initial_scale (float, optional) -- The initial loss scale of AMP. Defaults to 2**16.
- min_scale (float, optional) -- The minimum loss scale of AMP. Defaults to 1.
- growth_factor (float, optional) -- The multiplication factor for increasing loss scale when using AMP. Defaults to 2.
- backoff_factor (float, optional) -- The multiplication factor for decreasing loss scale when using AMP. Defaults to 0.5.
- growth_interval (int, optional) -- The number of steps to increase loss scale when no overflow occurs when using AMP. Defaults to 1000.
- hysteresis (int, optional) -- The number of overflows before decreasing loss scale when using AMP. Defaults to 2.
- max_scale (float, optional) -- The maximum loss scale of AMP. Defaults to 2**32.
- max_norm (float, optional) -- Maximum norm for gradient clipping. Defaults to 0.
- broadcast_buffers (bool, optional) -- Whether to broadcast buffers in the beginning of training when using DDP. Defaults to True.
- ddp_bucket_cap_mb (int, optional) -- The bucket size in MB when using DDP. Defaults to 25.
- find_unused_parameters (bool, optional) -- Whether to find unused parameters when using DDP. Defaults to False.
- check_reduction (bool, optional) -- Whether to check reduction when using DDP. Defaults to False.
- gradient_as_bucket_view (bool, optional) -- Whether to use gradient as bucket view when using DDP. Defaults to False.
- static_graph (bool, optional) -- Whether to use static graph when using DDP. Defaults to False.
- zero_bucket_size_in_m (int, optional) -- Gradient reduce bucket size in million elements when using ZeRO. Defaults to 12.
- cpu_offload (bool, optional) -- Whether to open cpu_offload when using ZeRO. Defaults to False.
- communication_dtype (torch.dtype, optional) -- Communication dtype when using ZeRO. If not specified, the dtype of param will be used. Defaults to None.
- overlap_communication (bool, optional) -- Whether to overlap communication and computation when using ZeRO. Defaults to True.
- custom_policy (Policy, optional) -- Custom policy for Shardformer. Defaults to None.
- pp_style (str, optional) -- The style for pipeline parallelism. Defaults to '1f1b'.
- num_model_chunks (int, optional) -- The number of model chunks for interleaved pipeline parallelism. Defaults to 1.
- gradient_checkpoint_config (GradientCheckpointConfig, optional) -- Configuration for gradient checkpointing. Defaults to None.
- enable_metadata_cache (bool, optional) -- Whether to enable metadata cache for pipeline parallelism. Defaults to True.
- make_vocab_size_divisible_by (int, optional) -- it's used when padding the vocabulary size, to make it choose an faster kenel. Default to 64.
- fp8_communication (bool, optional) -- Whether to enable fp8 communication. Defaults to False.
- use_fp8 (bool, optional) -- Whether to enable fp8 mixed precision training. Defaults to False.
- overlap_p2p (bool, optional) -- Whether to overlap the p2p communication in pipeline parallelism
- inner_ring_size (int, optional) -- The inner ring size of 2D Ring Attention when sp mode is "ring_attn". It's advisable to not tune this (especially in single-node settings) and let it be heuristically set based on topology by default.
Plugin for Hybrid Parallel Training. Tensor parallel, pipeline parallel and data parallel(DDP/ZeRO) can be picked and combined in this plugin. The size of tp and pp should be passed in by user, then the size of dp is automatically calculated from dp_size = world_size / (tp_size * pp_size).
from colossalai.booster import Booster
from colossalai.booster.plugin import HybridParallelPlugin
model, train_dataset, optimizer, criterion = ...
plugin = HybridParallelPlugin(tp_size=2, pp_size=2)
train_dataloader = plugin.prepare_dataloader(train_dataset, batch_size=8)
booster = Booster(plugin=plugin)
model, optimizer, criterion, train_dataloader, _ = booster.boost(model, optimizer, criterion, train_dataloader)
function
prepare_dataloader
- dataset (torch.utils.data.Dataset) -- The dataset to be loaded.
- shuffle (bool, optional) -- Whether to shuffle the dataset. Defaults to False.
- seed (int, optional) -- Random worker seed for sampling, defaults to 1024.
add_sampler -- Whether to add
DistributedDataParallelSamplerto the dataset. Defaults to True. - drop_last (bool, optional) -- Set to True to drop the last incomplete batch, if the dataset size is not divisible by the batch size. If False and the size of dataset is not divisible by the batch size, then the last batch will be smaller, defaults to False.
- pin_memory (bool, optional) -- Whether to pin memory address in CPU memory. Defaults to False.
- num_workers (int, optional) -- Number of worker threads for this dataloader. Defaults to 0.
- kwargs (dict) -- optional parameters for
torch.utils.data.DataLoader, more details could be found in DataLoader.
Prepare a dataloader for distributed training. The dataloader will be wrapped by torch.utils.data.DataLoader and torch.utils.data.DistributedSampler.
Returns: [torch.utils.data.DataLoader`]: A DataLoader used for training or testing.
Torch DDP Plugin
More details can be found in Pytorch Docs.
class
colossalai.booster.plugin.TorchDDPPlugin
- broadcast_buffers (bool, optional) -- Whether to broadcast buffers in the beginning of training. Defaults to True.
- bucket_cap_mb (int, optional) -- The bucket size in MB. Defaults to 25.
- find_unused_parameters (bool, optional) -- Whether to find unused parameters. Defaults to False.
- check_reduction (bool, optional) -- Whether to check reduction. Defaults to False.
- gradient_as_bucket_view (bool, optional) -- Whether to use gradient as bucket view. Defaults to False.
- static_graph (bool, optional) -- Whether to use static graph. Defaults to False.
- fp8_communication (bool, optional) -- Whether to enable fp8 communication. Defaults to False.
Plugin for PyTorch DDP.
from colossalai.booster import Booster
from colossalai.booster.plugin import TorchDDPPlugin
model, train_dataset, optimizer, criterion = ...
plugin = TorchDDPPlugin()
train_dataloader = plugin.prepare_dataloader(train_dataset, batch_size=8)
booster = Booster(plugin=plugin)
model, optimizer, train_dataloader, criterion = booster.boost(model, optimizer, train_dataloader, criterion)
Torch FSDP Plugin
⚠ This plugin is not available when torch version is lower than 1.12.0.
⚠ This plugin does not support save/load sharded model checkpoint now.
⚠ This plugin does not support optimizer that use multi params group.
More details can be found in Pytorch Docs.
class
colossalai.booster.plugin.TorchFSDPPlugin
- See https --//pytorch.org/docs/stable/fsdp.html for details.
Plugin for PyTorch FSDP.
from colossalai.booster import Booster
from colossalai.booster.plugin import TorchFSDPPlugin
model, train_dataset, optimizer, criterion = ...
plugin = TorchFSDPPlugin()
train_dataloader = plugin.prepare_train_dataloader(train_dataset, batch_size=8)
booster = Booster(plugin=plugin)
model, optimizer, train_dataloader, criterion = booster.boost(model, optimizer, train_dataloader, criterion)