Integrate Mixture-of-Experts Into Your Model
Author: Haichen Huang
Example Code
Related Paper
- Switch Transformers: Scaling to Trillion Parameter Models with Simple and Efficient Sparsity
- Go Wider Instead of Deeper
Introduction
Since the advent of Switch Transformer, the AI community has found Mixture of Experts (MoE) a useful technique to enlarge the capacity of deep learning models.
Colossal-AI provides an early access version of parallelism specifically designed for MoE models. The most prominent advantage of MoE in Colossal-AI is convenience. We aim to help our users to easily combine MoE with model parallelism and data parallelism.
However, the current implementation has two main drawbacks now. The first drawback is its poor efficiency in large batch size and long sequence length training. The second drawback is incompatibility with tensor parallelism. We are working on system optimization to overcome the training efficiency problem. The compatibility problem with tensor parallelism requires more adaptation, and we will tackle this issue in the future.
Here, we will introduce how to use MoE with model parallelism and data parallelism.
Table of Content
In this tutorial we will cover:
- Set up MoE running environment
- Create MoE layer
- Train your model
We provided the example code for this tutorial in ColossalAI-Examples. This example uses WideNet as an example of MoE-based model.
Set up MoE running environment
In your project folder, create a config.py.
This file is to specify some features you may want to use to train your model. In order to enable MoE, you need to add a dict called parallel and specify the value of key moe. You can assign a value for the key size of moe, which represents the model parallel size of experts (i.e. the number of experts in one group to parallelize training).
For example, if the size is 4, 4 processes will be assigned to 4 consecutive GPUs and these 4 processes form a moe model parallel group. Each process on the 4 GPUs will only get a portion of experts. Increasing the model parallel size will reduce communication cost, but increase computation cost in each GPU and activation cost in memory. The total data parallel size is auto-detected and set as the number of GPUs by default.
MOE_MODEL_PARALLEL_SIZE = ...
parallel = dict(
moe=dict(size=MOE_MODEL_PARALLEL_SIZE)
)
If MOE_MODEL_PARALLEL_SIZE = E and set the number of experts as E where E is a constant number, the process flow of forward pass of a transformer encoder in a model parallel group is shown below.
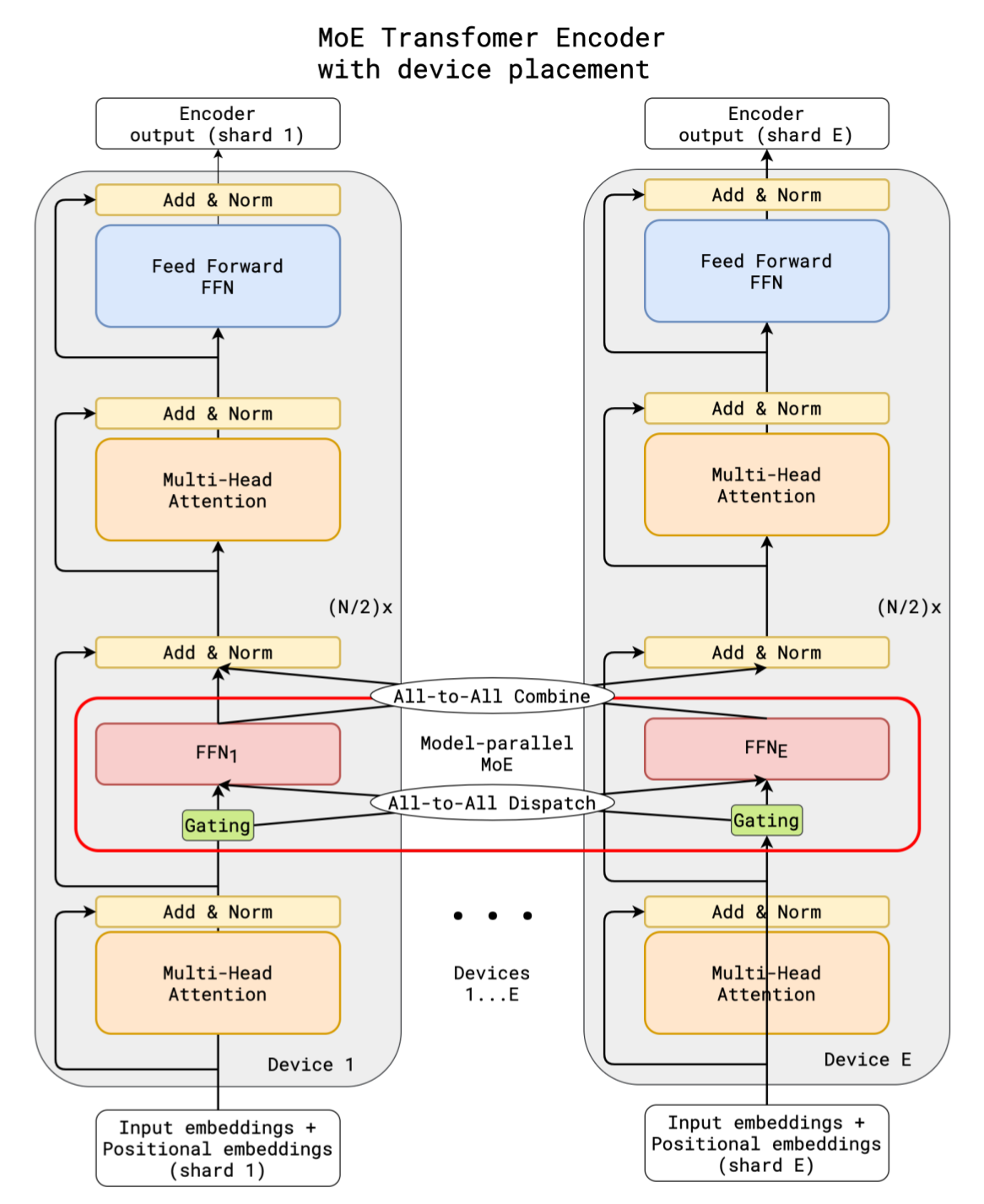
Since all experts are allocated to all GPUs in a model parallel group and a GPU only owns a portion of experts,
original data parallel groups are no longer correct for the parameters of experts during gradient handling in backward pass anymore.
So we create a new kind of parallel group called moe data parallel group.
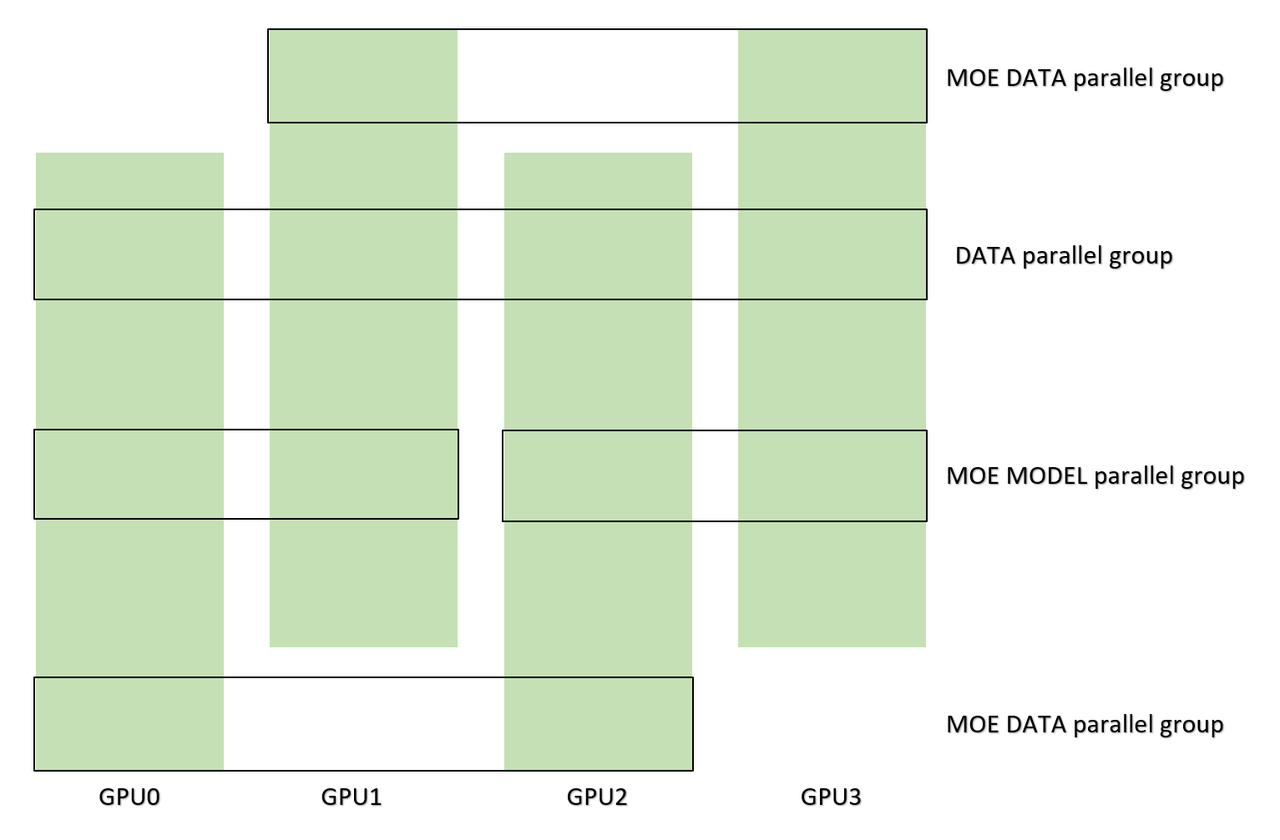
The difference among different kinds of parallel group, when the configuration is set as WORLD_SIZE=4,
MOE_MODEL_PARALLEL_SIZE=2, is shown here.
As for gradient handling, we provide MoeGradientHandler to all-reduce every parameter of the model.
If you use colossalai.initialize function to create your training engine, the MoE gradient handler will be added to your engine automatically.
Otherwise, you should take care of gradient by yourself.
All parameters of MoE running environment are stored in colossalai.global_variables.moe_env.
You can access your configuration parameters to check whether your setup is correct.
from colossalai.global_variables import moe_env
Create MoE layer
You can create a MoE layer from colossalai.nn.moe.
But before doing that, you should set up random seeds for all processes like this.
from colossalai.context.random import moe_set_seed
from model_zoo.moe.models import Widenet
moe_set_seed(42)
model = Widenet(num_experts=4, capacity_factor=1.2)
moe_set_seed will set different seed for different processes in a moe model parallel group.
This helps initialize parameters in experts.
Then create an instance of experts and an instance of router.
Here is the example in model zoo.
from colossalai.nn.layer.moe import Experts, MoeLayer, Top2Router, NormalNoiseGenerator
noisy_func = NormalNoiseGenerator(num_experts)
shared_router = Top2Router(capacity_factor,
noisy_func=noisy_func)
shared_experts = Experts(expert=VanillaFFN,
num_experts=num_experts,
**moe_mlp_args(
d_model=d_model,
d_ff=d_ff,
drop_rate=drop_rate
))
ffn=MoeLayer(dim_model=d_model, num_experts=num_experts,
router=shared_router, experts=shared_experts)
Inside the initialization of Experts, the local expert number of each GPU will be calculated automatically. You just need to specify the class of each expert and its parameters used in its initialization. As for routers, we have provided top1 router and top2 router. You can find them in colossalai.nn.layer.moe. After creating the instance of experts and router, the only thing initialized in Moelayer is gate module. More definitions of each class can be found in our API document and code.
Train Your Model
Do not to forget to use colossalai.initialize function in colossalai to add gradient handler for the engine.
We handle the back-propagation of MoE models for you.
In colossalai.initialize, we will automatically create a MoeGradientHandler object to process gradients.
You can find more information about the handler MoeGradientHandler in colossal directory.
The loss criterion should be wrapped by Moeloss to add auxiliary loss of MoE. Example is like this.
criterion = MoeLoss(
aux_weight=0.01,
loss_fn=nn.CrossEntropyLoss,
label_smoothing=0.1
)
Finally, just use trainer or engine in colossalai to do your training.
Otherwise, you should take care of gradient by yourself.