Meet Gemini:The Heterogeneous Memory Manager of Colossal-AI
Author: Jiarui Fang, Yang You
Brief
When you only have a few GPUs for large model training tasks, heterogeneous training is the most effective approach. By accommodating model data in CPU and GPU and moving the data to the computing device when necessary, it can breakthrough the GPU memory wall by using GPU and CPU memory (composed of CPU DRAM or nvme SSD memory) together at the same time. Moreover, the model scale can be further improved by combining heterogeneous training with the other parallel approaches, such as data parallel, tensor parallel and pipeline parallel . We now describe the design details of Gemini, the heterogeneous memory space manager of Colossal-AI. Its idea comes from PatrickStar, which has been adapted to Colossal-AI.
Usage
At present, Gemini supports compatibility with ZeRO parallel mode, and it is really simple to use Gemini: Inject the features of GeminiPlugin into training components with booster. More instructions of booster please refer to usage of booster.
from torchvision.models import resnet18
from colossalai.booster import Booster
from colossalai.zero import ColoInitContext
from colossalai.booster.plugin import GeminiPlugin
plugin = GeminiPlugin(placement_policy='cuda', strict_ddp_mode=True, max_norm=1.0, initial_scale=2**5)
booster = Booster(plugin=plugin)
ctx = ColoInitContext()
with ctx:
model = resnet18()
optimizer = HybridAdam(model.parameters(), lr=1e-3)
criterion = lambda x: x.mean()
model, optimizer, criterion, _, _ = booster.boost(model, optimizer, criterion)
)
Note that Gemini and parallel strategies such as tensor parallelism, data parallelism, pipeline parallelism and zero should be decoupled. However, Colossal-AI requires users to use Gemini with ZeRO. Although they are not necessarily coupled, we will improve it in the near future.
Concepts
OP(OPerator):operation of a neural network layer, such as linear, LayerNorm, etc. The operator can be a forward propagation calculation or a back-propagation calculation.
Neural networks must manage two types of training data during training. model data: consists of parameters, gradients and optimizer states, and its scale is related to the definition of model structure.
Non-model data: mainly composed of the intermediate tensor generated by the operator and the temporary variables of the operator. Non-model data changes dynamically according to the configuration of training tasks, such as batch size. Model data and non-model data compete with each other for GPU memory.
Design Details
In some solutions, the Zero-offload adopted by DeepSpeed statically divides model data between CPU and GPU memory, and their memory layout is constant for different training configurations. As shown on the left of the figure below, when the GPU memory is insufficient to meet its corresponding model data requirements, the system will crash even if there is still available memory on the CPU at that time. While Colossal-AI can complete the training by moving part of the model data to the CPU.
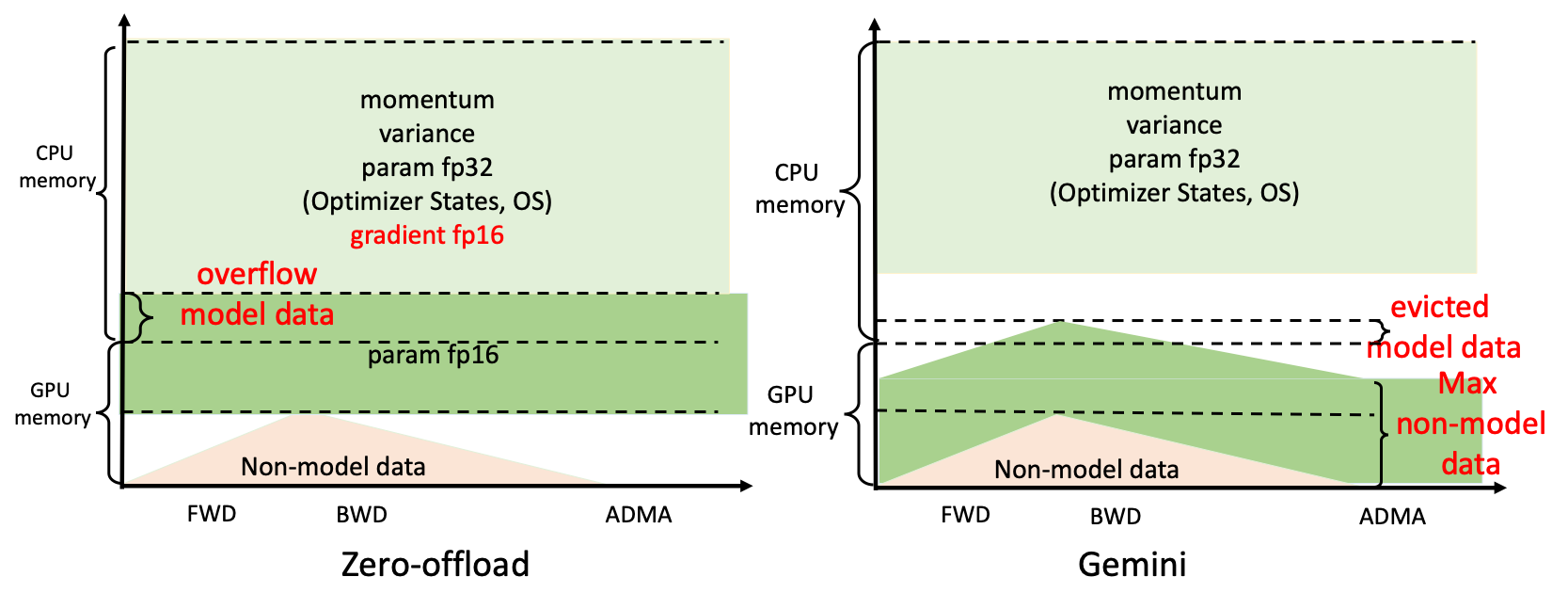
Colossal-AI designed Gemini, just like two-stars, which manages the memory space of CPU and GPU efficiently. It can make the tensor dynamically distributed in the storage space of CPU-GPU during training, so that the model training can break through the memory wall of GPU. The memory manager consists of two parts: MemStatsCollector (MSC) and StatefulTensorMgr (STM).
We take advantage of the iterative characteristics of the deep learning network training process. We divide iterations into two stages: warmup and non-warmup. One or several iterative steps at the beginning belong to the warmup stage, and the other iterative steps belong to the non-warmup stage. In the warmup stage, we collect information for the MSC, while in the non-warmup stage, STM gets the information collected by the MSC to move the tensor, so as to minimize the CPU-GPU data movement volume.
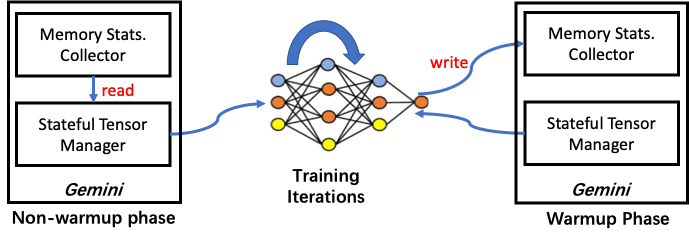
StatefulTensorMgr
STM manages the information of all model data tensors. In the process of model construction, Colossal-AI registers all model data tensors with STM. The memory manager marks each tensor with state information. The state set includes three types: HOLD, COMPUTE and FREE. The functions of STM are as follows:
Query memory usage:by traversing the locations of all tensors in heterogeneous space, obtain the memory occupation of CPU and GPU by model data.
Transition tensor state: it marks the tensor as COMPUTE state before each model data tensor participates in the operator calculation, and as HOLD state after calculation. The FREE state marked if the tensor is no longer in use.
Adjust tensor position:tensor manager ensures that the tensor in COMPUTE state is placed on the computing device. If the storage space of the computing device is insufficient, it is necessary to move some tensors in HOLD state to other devices for storage. Tensor eviction strategy requires information from MSC, which will be introduced later.
MemStatsCollector
In the warmup stage, the memory information statistician monitors the memory usage of model data and non-model data in CPU and GPU for reference in the non-warmup stage. We can obtain the memory usage of model data at a certain time by querying STM. However, the memory usage of non-model data is difficult to obtain. Owing to the life cycle of non-model data not being managed by users, the existing deep learning framework does not expose the tracking interface of non-model data to users. MSC obtains the usage of CPU and GPU memory by non-model in the warmup stage through sampling. The specific methods are as follows:
We trigger the memory sampling operation at the beginning and end of the operator. We call this time point sampling moment, and the time between the two sampling moments is called period. The calculation process is a black box. Due to the possible allocation of temporary buffer, the memory usage is very complex. However, we can accurately obtain the maximum memory usage of the system during the period. The use of non-model data can be obtained by the maximum memory use of the system between two statistical moments-model memory use.
How do we design the sampling time. Before we choose model data layout adjust of preOp. As shown in the figure below. We sample the system memory used of the previous period and the model data memory used of the next period. The parallel strategy will cause obstacles to the work of MSC. As shown in the figure, for example, for ZeRO or Tensor Parallel, because gathering model data is required before OP calculation, it will bring additional memory requirements. Therefore, we require to sample the system memory before the model data changes, so that the MSC will capture the model change memory of preOp within a period. For example, in period 2-3, we consider the memory changes brought by tensor gather and shard.
Although the sampling time can be placed in other locations, such as excluding the new information of the change of the gather buffer, it will cause trouble. There are differences in the implementation of Op in different parallel modes. For example, for Linear Op, gather buffer in Tensor Parallel is allocated in Op. For ZeRO, the allocation of gather buffer is in PreOp. Sampling at the beginning of PreOp helps to unify the two situations.
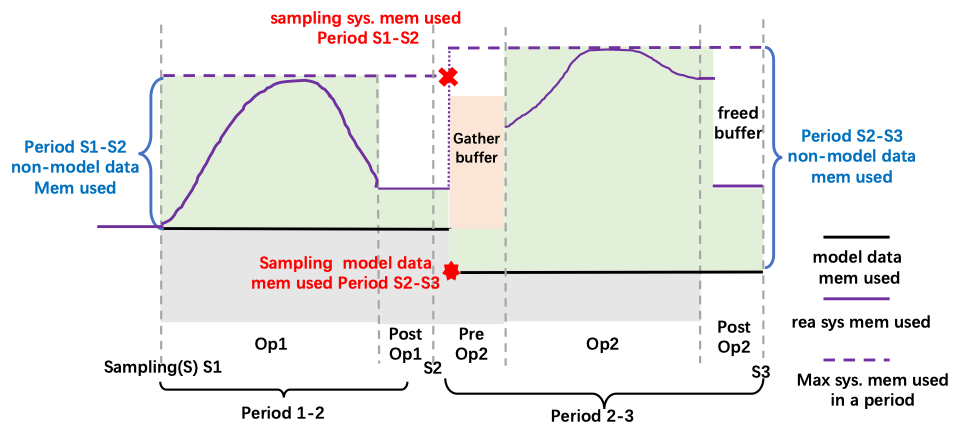
Tensor Eviction Strategy
The important duty of MSC is to adjust the tensor layout position. For example, at S2 in the figure above, we reduce the model data on the device, and meet the peak memory requirement calculated in period 2-3.
In the warmup stage, since we haven't finished a complete iteration yet, we don't know actual memory occupation. At this time, we limit the upper bound of memory usage of the model data. For example, only 30% of the GPU memory can be used. This ensures that we can successfully complete the warmup state.
In the non-warmup stage, we need to use the memory information of non-model data collected in the warm-up stage to reserve the peak memory required by the computing device for the next Period, which requires us to move some model tensors. In order to avoid frequent replacement of the same tensor in and out of the CPU-GPU, causing a phenomenon similar to cache thrashing. Using the iterative characteristics of DNN training, we design the OPT cache swap out strategy. Specifically, in the warmup stage, we record the sampling time required by each tensor computing device. If we need to expel some HOLD tensors, we will choose the latest tensor needed on this device as the victim.